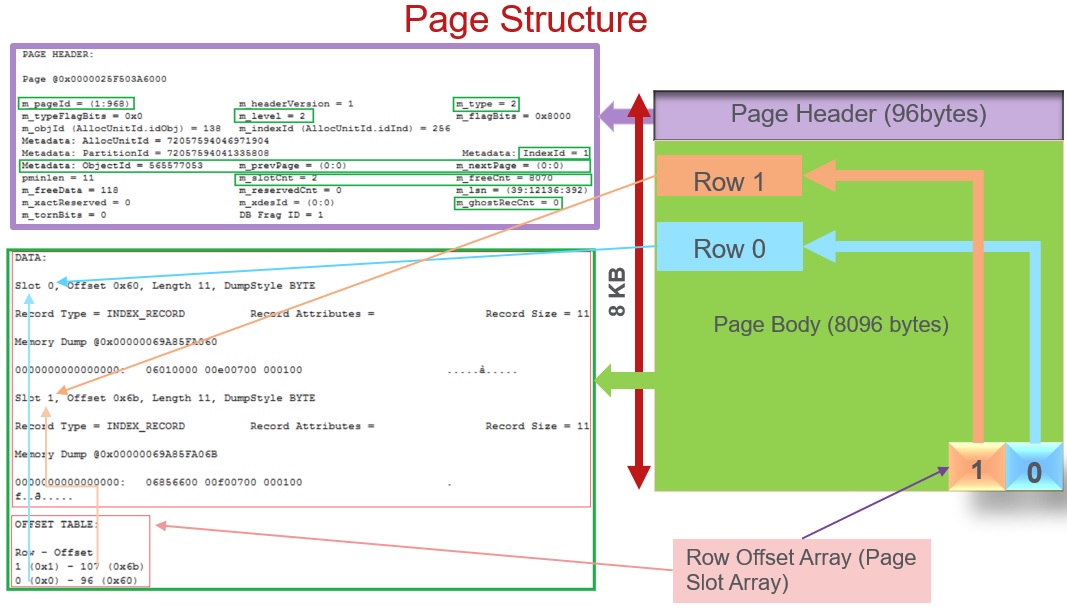
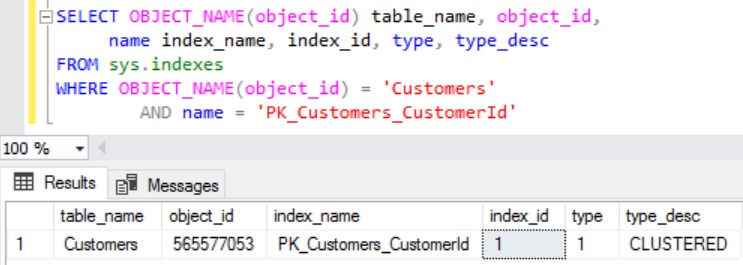
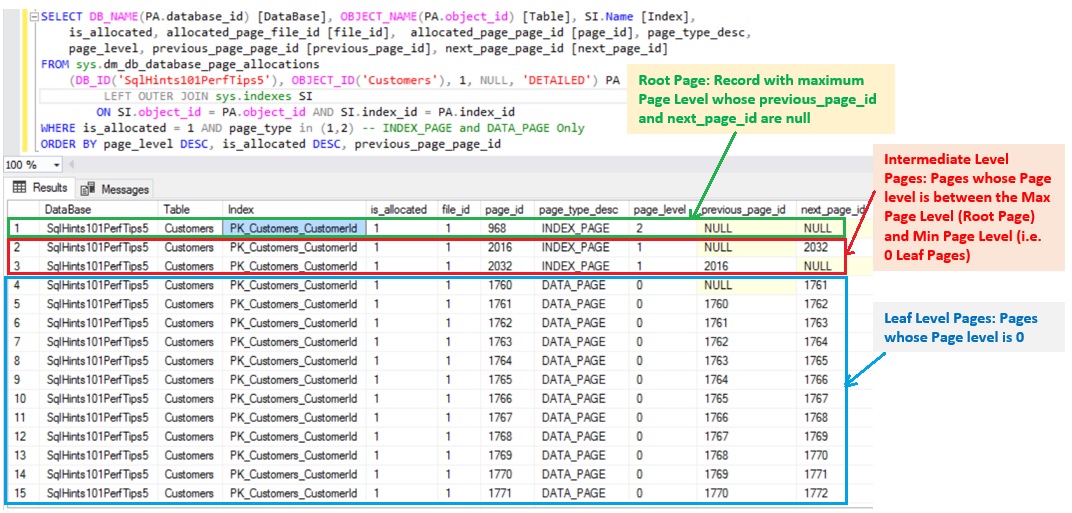
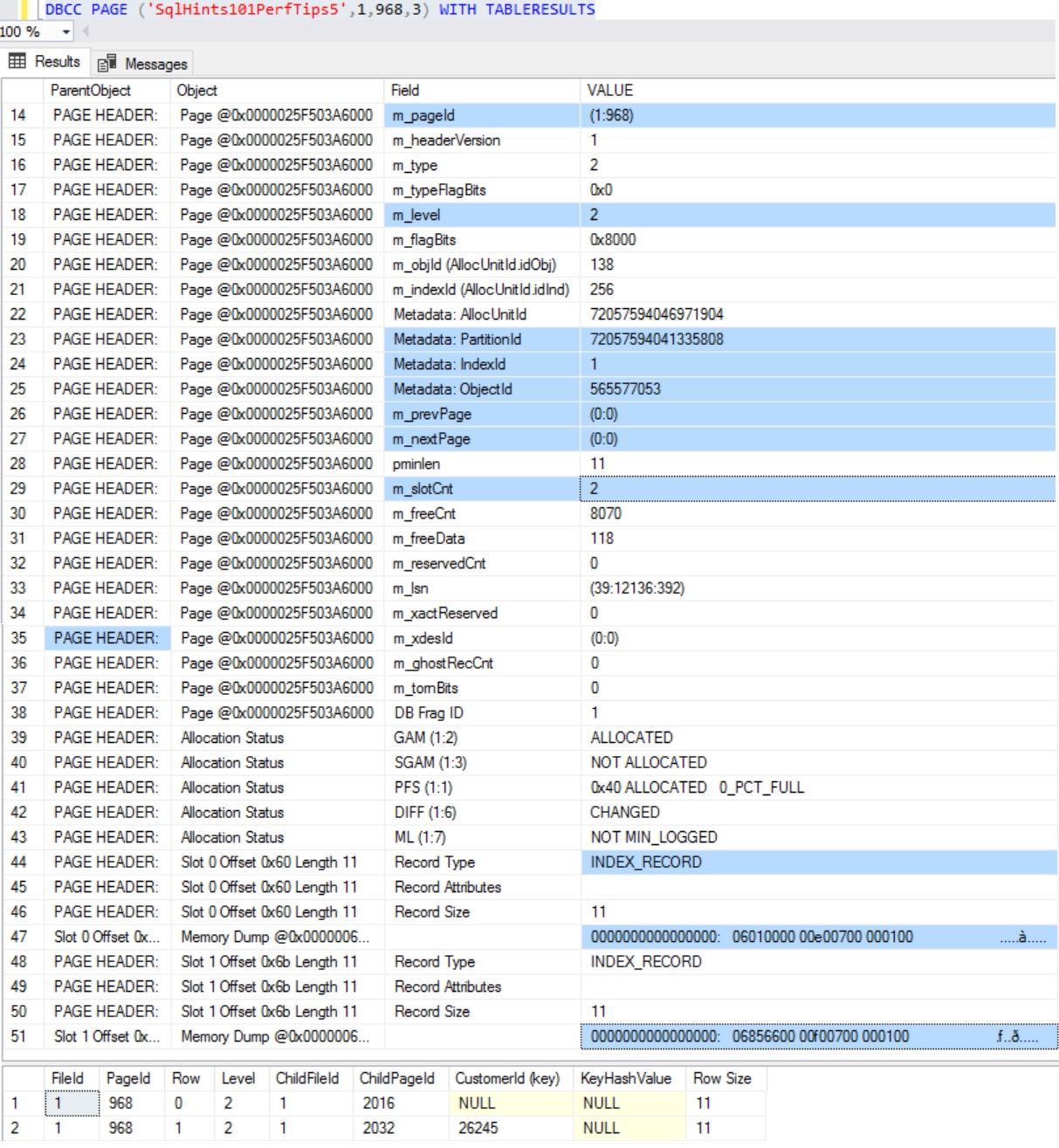
Do we need to include a Clustered Index Column too in a Non-Clustered Index to make it as a Covering Index for a Query? Tip 7: Sql Server 101 Performance Tuning Tips and Tricks
Answer to this question is NO, because by default when we create a Non-Clustered Index in Sql Server it adds the Clustered Index Key Column values too in the Non-Clustered Index.
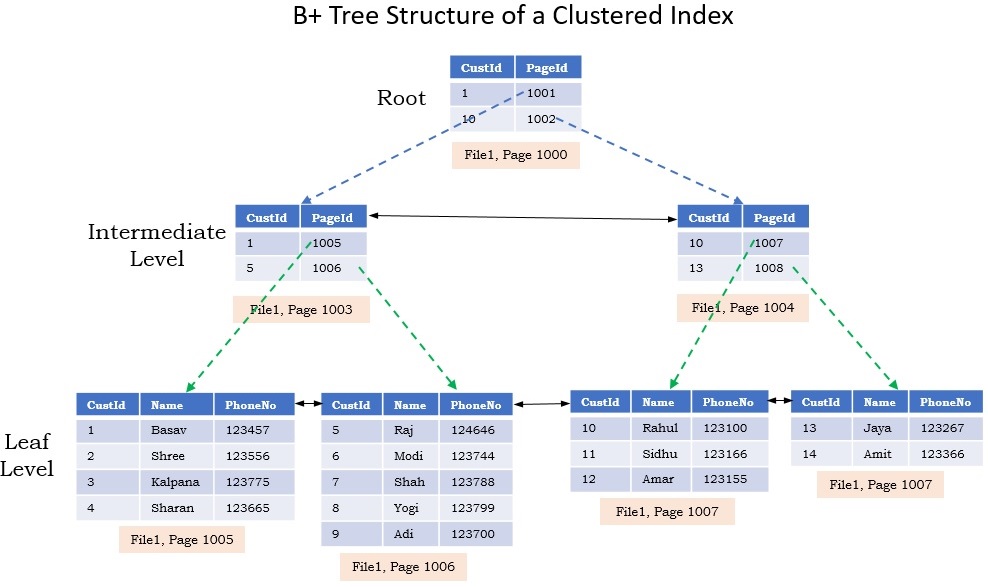
Let us understand this with an example. Let us create a Customer table with Clustered Index on the CustomerId column as shown in the below image with sample 35K records by executing the following script.

CREATE DATABASE SqlHints101PerfTips7
GO
USE SqlHints101PerfTips7
GO
--Create Demo Table Customers
CREATE TABLE dbo.Customers (
CustomerId INT IDENTITY(1,1) NOT NULL,
FirstName VARCHAR(50),
LastName VARCHAR(50),
PhoneNumber VARCHAR(10),
EmailAddress VARCHAR(50),
CreationDate DATETIME
)
GO
--Populate 35K dummy customer records
INSERT INTO dbo.Customers (FirstName, LastName, PhoneNumber, EmailAddress, CreationDate)
SELECT TOP 35000 REPLACE(NEWID(),'-',''), REPLACE(NEWID(),'-',''),
CAST( CAST(ROUND(RAND(CHECKSUM(NEWID()))*1000000000+4000000000,0) AS BIGINT) AS VARCHAR(10)),
REPLACE(NEWID(),'-','') + '@gmail.com',
DATEADD(HOUR,CAST(RAND(CHECKSUM(NEWID())) * 19999 as INT) + 1 ,'2006-01-01')
FROM sys.all_columns c1
CROSS JOIN sys.all_columns c2
GO
--Update one customer record with some known values
UPDATE dbo.Customers
SET FirstName = 'Basavaraj', LastName = 'Biradar',
PhoneNumber = '4545454545', EmailAddress = 'basav@gmail.com'
WHERE CustomerId = 10000
GO
--Create a PK and a Clustered Index on CustomerId column
ALTER TABLE dbo.Customers
ADD CONSTRAINT PK_Customers_CustomerId
PRIMARY KEY CLUSTERED (CustomerId)
GO
Assume that we have a requirement to get the CustomerId for the given customer FirstName and LastName. We can write a query like below to get the CustomerId by Customers FirstName and LastName. Let us now enable the execution plan in the Sql Server Management Studio by pressing the key stroke CTRL + M and then execute the following query.
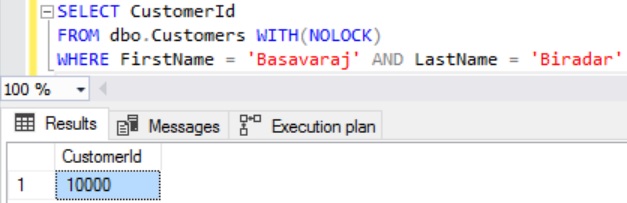
SELECT CustomerId FROM dbo.Customers WITH(NOLOCK) WHERE FirstName = 'Basavaraj' AND LastName = 'Biradar'
RESULT:
EXECUTION PLAN:
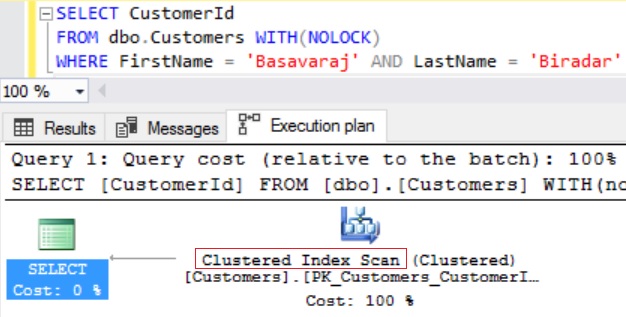
From the above execution plan we can see that this query is doing Clustered Index Scan (i.e. Table Scan). Now let us create a covering index (i.e. an index containing all queried columns) for this query so that it gives result from this Covering Index itself without requiring it to be looked-up into the Clustered Index. Now from the query we can see that it is referring to three columns i.e. FirstName, LastName and CustomerId. Out of these three columns CustomerId column is a Clustered Index column and other two columns (i.e. FirstName and LastName) are non-indexed column. Now comes doubt in the mind, to make a new index a Covering Index for the above query do I need to add the CustomerId column too in the list of columns in the new index apart from FirstName and LastName columns. The answer to this question is, we don’t need to add CustomerId column to the new index as it is a Clustered Index column. Let us understand this with an example. Now create a Composite non-clustered index on the FirstName and LastName column without CustomerId column by executing the following script.
--Create a non-clustered index on FirstName and LastName column
CREATE NONCLUSTERED INDEX IX_Customers_FirstName_LastName
ON dbo.Customers (FirstName, LastName)
GO
Now execute the above select statement once again and verify whether this new index is a Covering index for this query
SELECT CustomerId FROM dbo.Customers WITH(NOLOCK) WHERE FirstName = 'Basavaraj' AND LastName = 'Biradar'
RESULT:
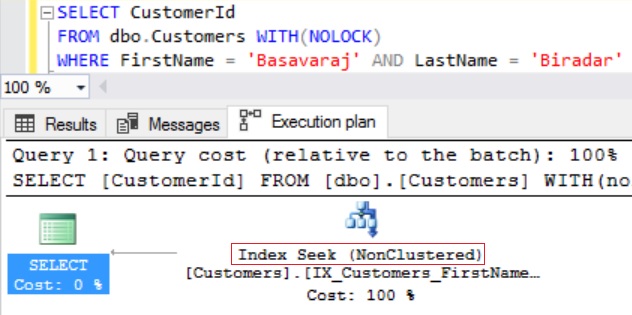
From the above execution plan we can see that Sql Server is doing the Seek of the newly created composite index IX_Customers_FirstName_LastName and we don’t see any key look-up into the Clustered index. So, this index is a covering index for the above query even though CustomerId column refereed in the SELECT statement is not part of the non-clustered index.
Let us inspect the index pages of the non-clustered index to see how Sql Server is adding Clustered Index Key Column values too in the Non-Clustered Index.
To explain this I will be using the below function which I have Created and explained in the previous article How to get an Index’s Root Page, Intermediate Pages and Leaf Pages Information?. This function uses the un-documented (i.e. feature that may change or removed without any notice or may produce un-expected result. So avoid using it in the Production environment) Dynamic Management Function sys.dm_db_database_page_allocations which is available from Sql Server 2012 onwards.
CREATE FUNCTION dbo.GetPagesOfBPlusTreeLevel(
@DBName VARCHAR(100), @TableName VARCHAR(100) = NULL, @IndexName VARCHAR(100) = NULL,
@PartionId INT = NULL, @MODE VARCHAR(20), @BPlusTreeLevel VARCHAR(20)
)
RETURNS
@IndexPageInformation TABLE (
[DataBase] VARCHAR(100), [Table] VARCHAR(100), [Index] VARCHAR(100),
[partition_id] INT, [file_id] INT, [page_id] INT, page_type_desc VARCHAR(100),
page_level INT, [previous_page_id] INT, [next_page_id] INT)
AS
BEGIN
DECLARE @MinPageLevelId INT = 0 , @MaxPageLevelId INT = 0, @IndexId INT = NULL
SELECT @IndexId = index_id
FROM sys.indexes
WHERE OBJECT_NAME(object_id) = @TableName AND name = @IndexName
IF @IndexId IS NULL
RETURN
IF @BPlusTreeLevel IN ('Root', 'Intermediate')
BEGIN
SELECT @MaxPageLevelId = (CASE WHEN @BPlusTreeLevel ='Intermediate' THEN MAX(page_level) - 1 ELSE MAX(page_level) END),
@MinPageLevelId = (CASE WHEN @BPlusTreeLevel ='Intermediate' THEN 1 ELSE MAX(page_level) END)
FROM sys.dm_db_database_page_allocations
(DB_ID(@DBName), OBJECT_ID(@TableName), @IndexId, @PartionId, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id AND SI.index_id = PA.index_id
WHERE is_allocated = 1 AND page_type in (1,2) -- INDEX_PAGE and DATA_PAGE Only
IF @MaxPageLevelId IS NULL OR @MaxPageLevelId = 0
RETURN
END
INSERT INTO @IndexPageInformation
SELECT DB_NAME(PA.database_id) [DataBase], OBJECT_NAME(PA.object_id) [Table], SI.Name [Index],
[partition_id], allocated_page_file_id [file_id], allocated_page_page_id [page_id], page_type_desc,
page_level, previous_page_page_id [previous_page_id], next_page_page_id [next_page_id]
FROM sys.dm_db_database_page_allocations
(DB_ID(@DBName), OBJECT_ID(@TableName), @IndexId, @PartionId, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id AND SI.index_id = PA.index_id
WHERE is_allocated = 1 AND page_type in (1,2) -- INDEX_PAGE and DATA_PAGE Only
AND page_level between @MinPageLevelId AND @MaxPageLevelId
ORDER BY page_level DESC, previous_page_page_id
RETURN
END
Inspect the content of the Non-Culstered Index B+ tree’s ROOT Page
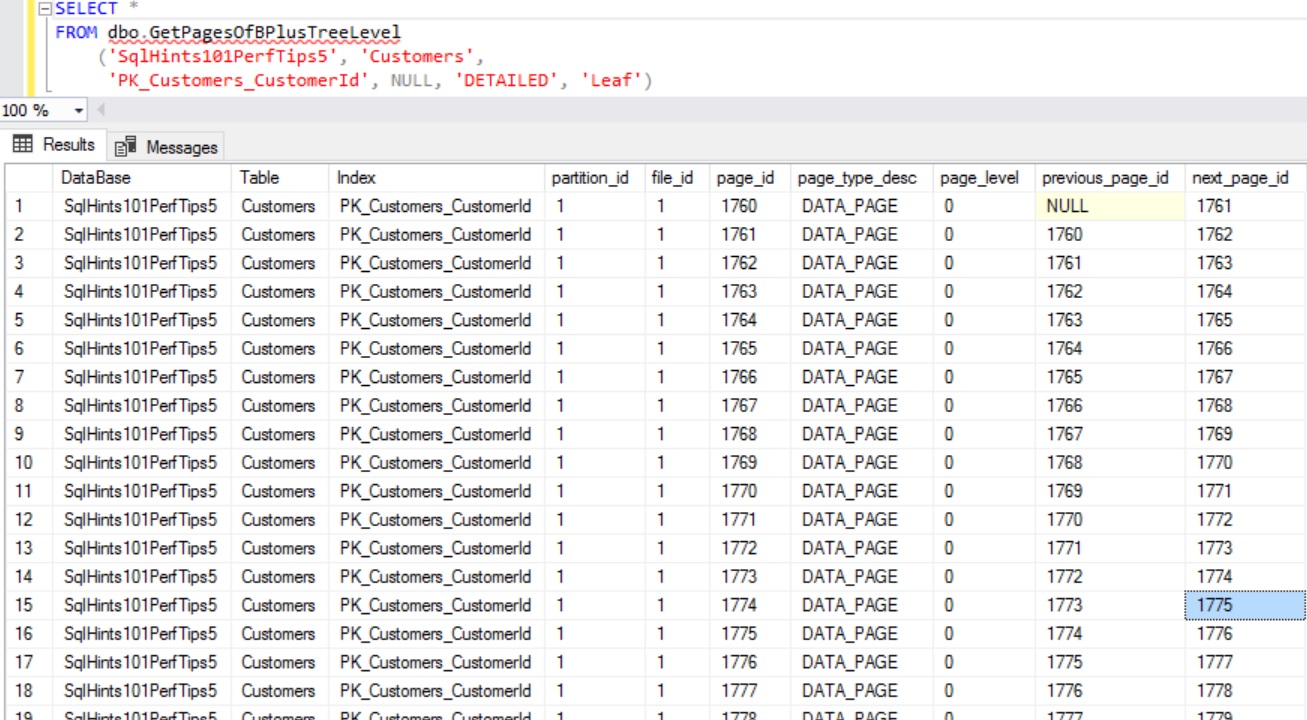
Let us use the above function GetPagesOfBPlusTreeLevel to get the Root page of a Non-Clustered Index. Execute the following statement to get the Root page of the Non-Clustered Index IX_Customers_FirstName_LastName on the Customers table.
SELECT *
FROM dbo.GetPagesOfBPlusTreeLevel ('SqlHints101PerfTips7',
'Customers', 'IX_Customers_FirstName_LastName',
NULL, 'DETAILED', 'Root')
RESULT:

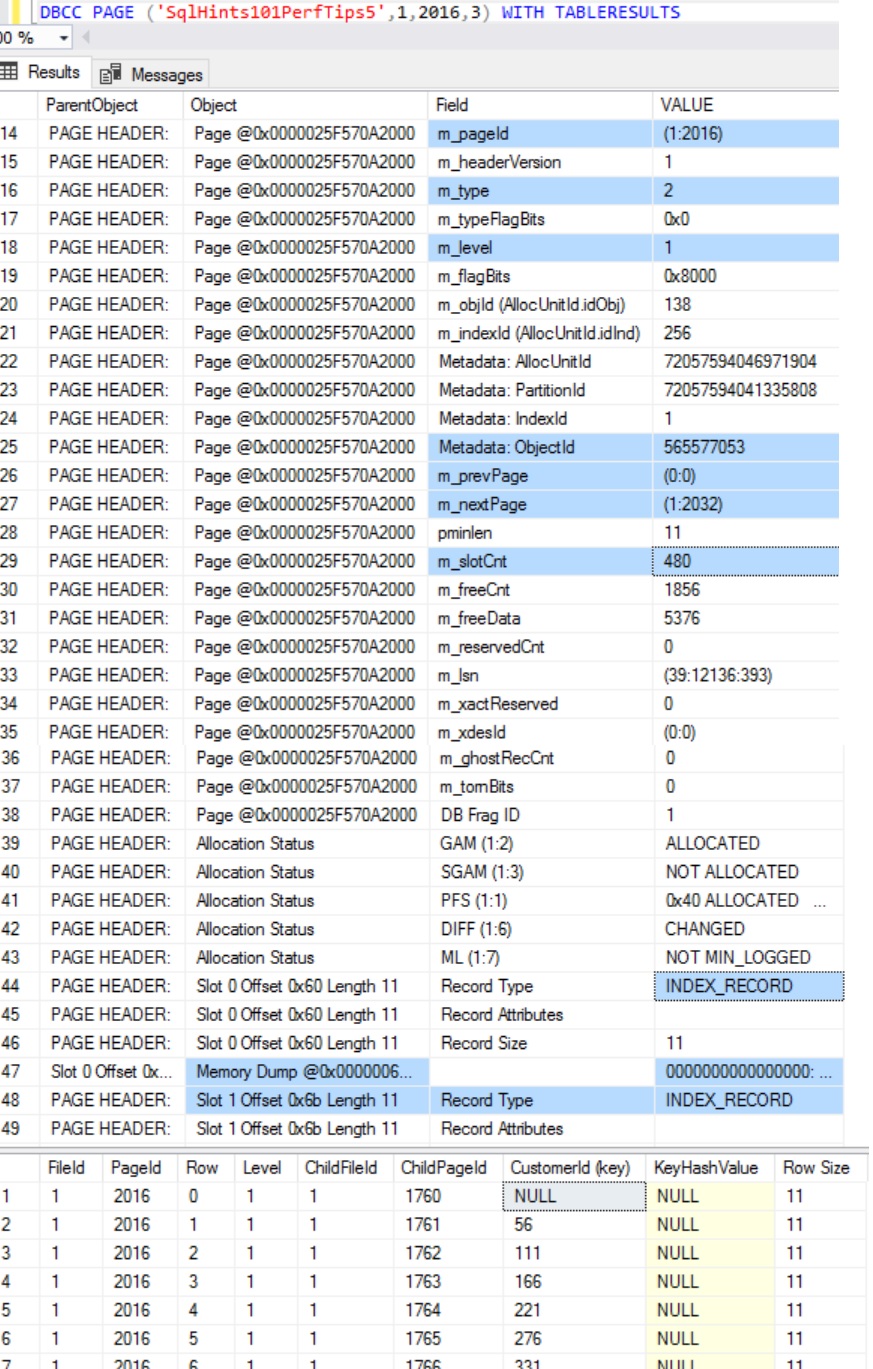
Let us use the DBCC PAGE Command which I have explained in the previous article How to Inspect the content of a DATA PAGE or INDEX PAGE? to inspect the content of the Root Page with FileId:1 and PageId:2810 of the Non-Clustered Index. Note: DBCC PAGE is an un-documented (i.e. feature that may change or removed without any notice or may produce un-expected result. So avoid using it in the Production environment) command.
DBCC PAGE ('SqlHints101PerfTips7', 1, 2810, 3) WITH TABLERESULTS
RESULT:
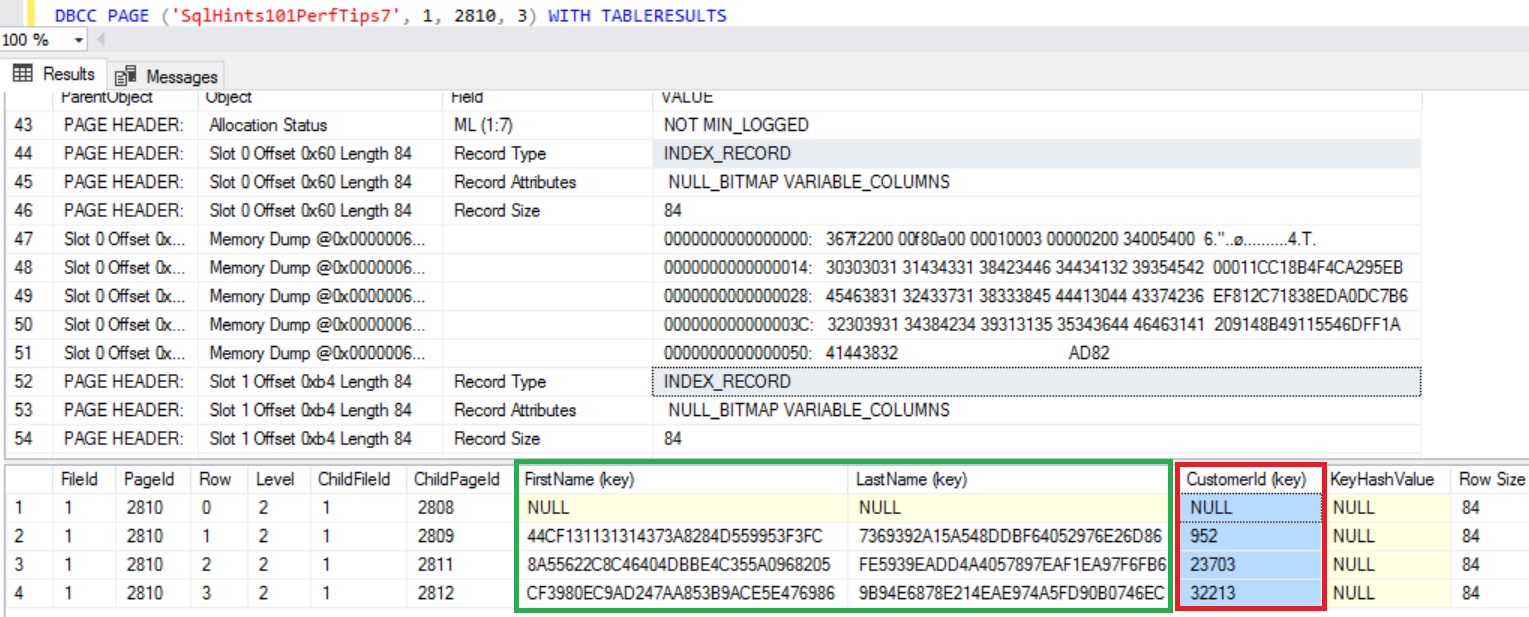
From the above result we can see that Clustered Index Key Column CustomerId value corresponding to the the Non-Clustered Index Key Columns is added in the non-clustered Index Root Page.
Inspect the content of the Non-Culstered Index B+ tree’s INTERMEDIATE Page
Let us use execute the following statement to get the INTERMEDIATE pages of a Non-Clustered Index IX_Customers_FirstName_LastName on the Customers table.
SELECT *
FROM dbo.GetPagesOfBPlusTreeLevel ('SqlHints101PerfTips7',
'Customers', 'IX_Customers_FirstName_LastName',
NULL, 'DETAILED', 'Intermediate')
RESULT:
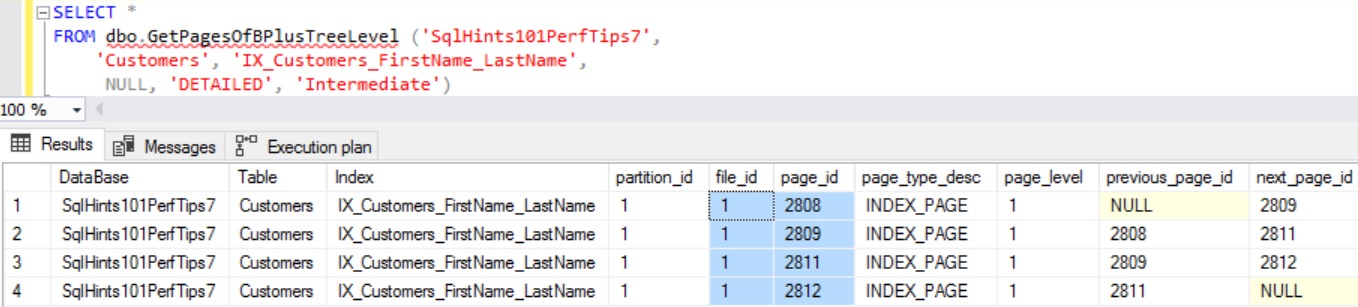
From the above result we can see that there are four Intermediate Level Pages for a Non-Clustered Index. Let us use the DBCC PAGE Command to inspect the content of the one of the Intermediate Level Page with FileId:1 and PageId:2811 of the Non-Clustered Index.
DBCC PAGE ('SqlHints101PerfTips7', 1, 2811, 3) WITH TABLERESULTS
RESULT:

From the above content of the Non-Clustered Index Intermediate Page, we can see that Clustered Index Key Column CustomerId value corresponding to the the Non-Clustered Index Key Columns is added in the non-clustered Index Intermediate Level Page.
Inspect the content of the Non-Culstered Index B+ tree’s LEAF Page
Let us use execute the following statement to get all the LEAF Pages of a Non-Clustered Index IX_Customers_FirstName_LastName on the Customers table.
SELECT *
FROM dbo.GetPagesOfBPlusTreeLevel ('SqlHints101PerfTips7',
'Customers', 'IX_Customers_FirstName_LastName',
NULL, 'DETAILED', 'Leaf')
RESULT:
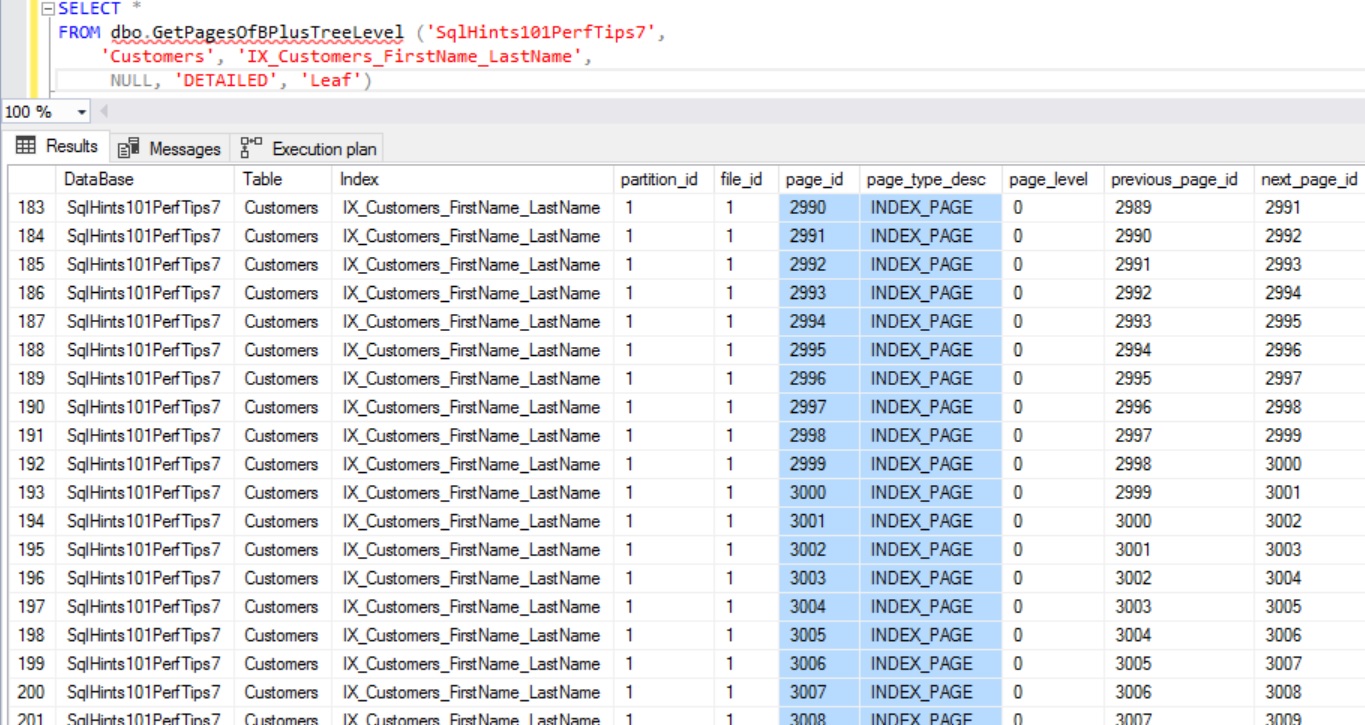
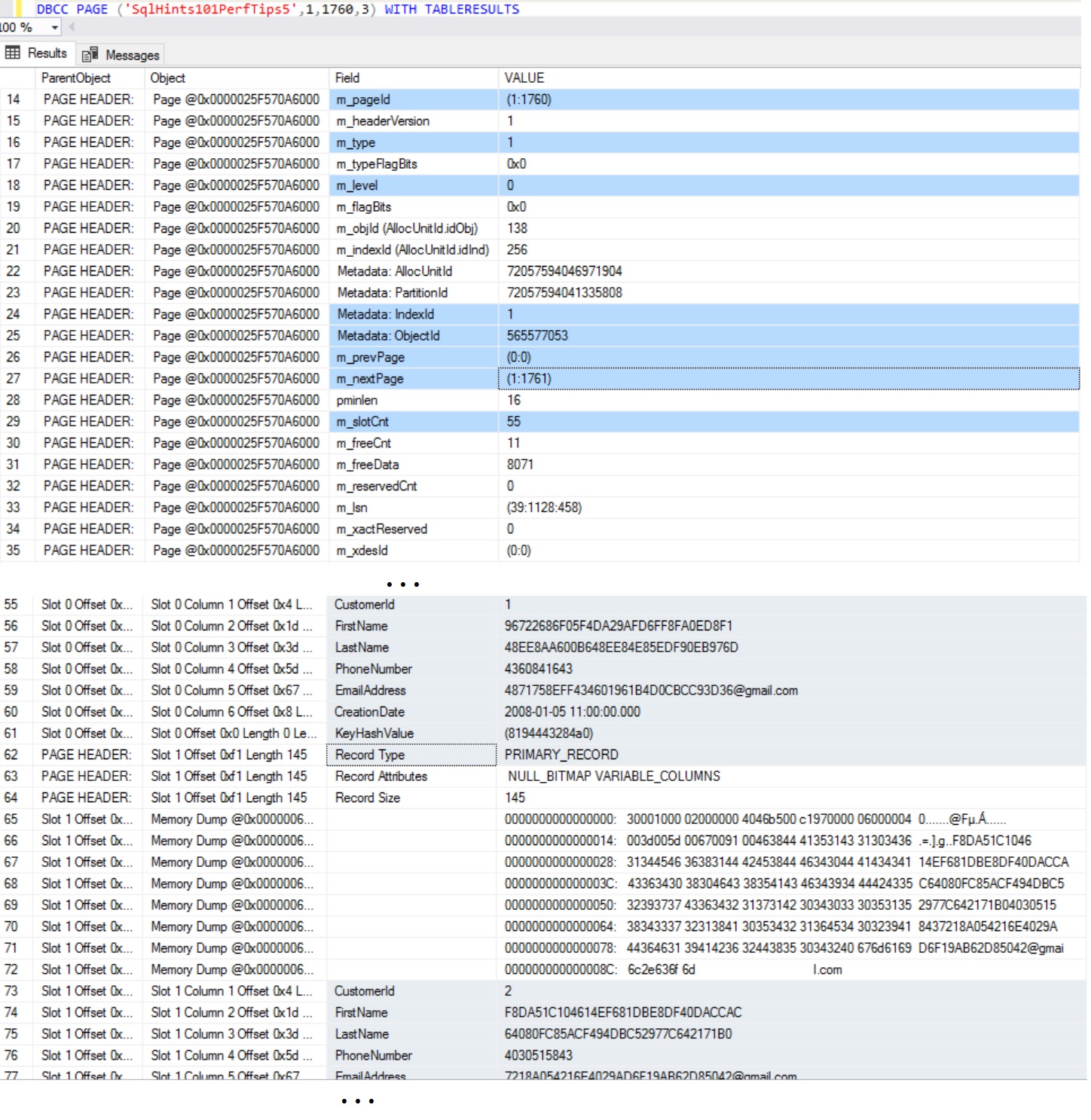
In this case there are 347 leaf pages. Let us inspect the content of the one of the Leaf Level Page with FileId:1 and PageId:3000 of the Non-Clustered Index.
DBCC PAGE ('SqlHints101PerfTips7', 1, 3000, 3) WITH TABLERESULTS
RESULT:
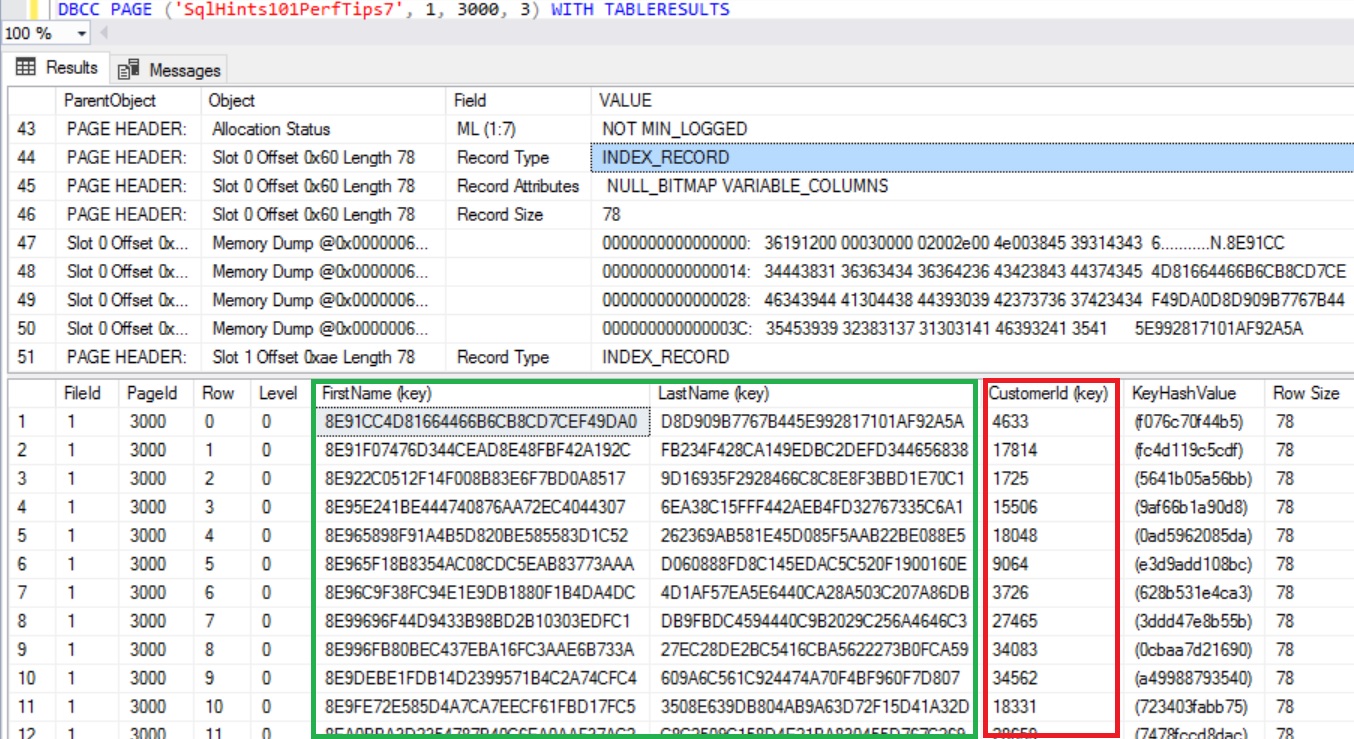
From the above content of the Non-Clustered Index Leaf Page, we can see that Clustered Index Key Column CustomerId value corresponding to the the Non-Clustered Index Key Columns is added in the non-clustered Index Leaf Level Page.
Conclusion:
From the above examples we can see that when we create a Non-Clustered Index, Sql Server adds the Clustered Index Key Column values Corresponding to the Non-Clustered Index Key columns in the Index Root, Intermediate and Leaf Level Pages. So, we don’t explicitly need to include a Clustered Index Key Column in a Non-Clustered Index to make it as a Covering Index for a Query. In case of an unique Non-Clustered Index the Root and Intermediate level pages will not have the Clustered Index Key Column Values in it, but it’s Leaf Page will have the Clustered Index Key Column value. In this way again for Unique Non-Clustered Index also we don’t explicitly need to add Clustered Index Key Column.