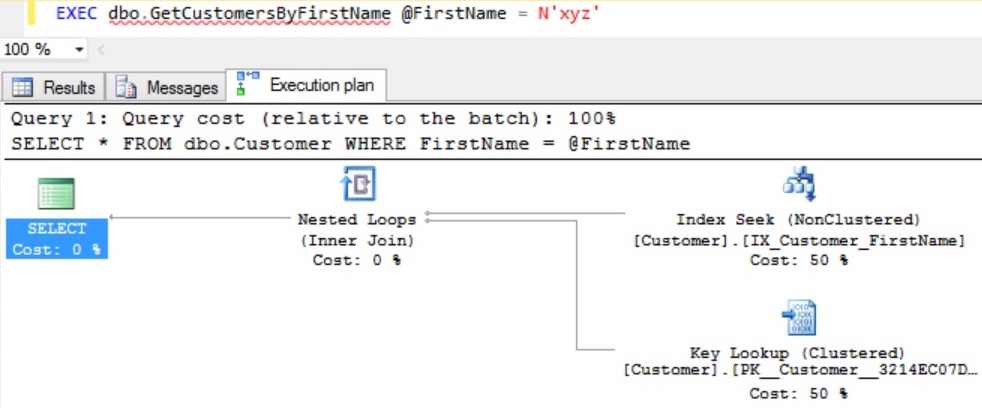
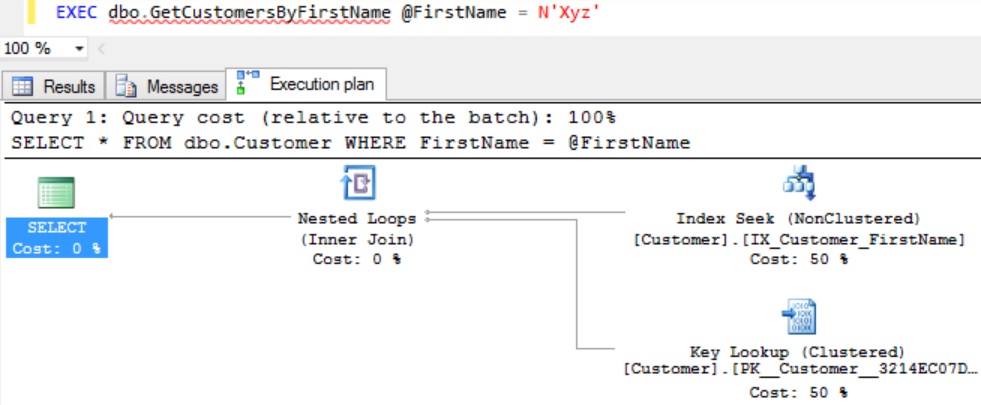
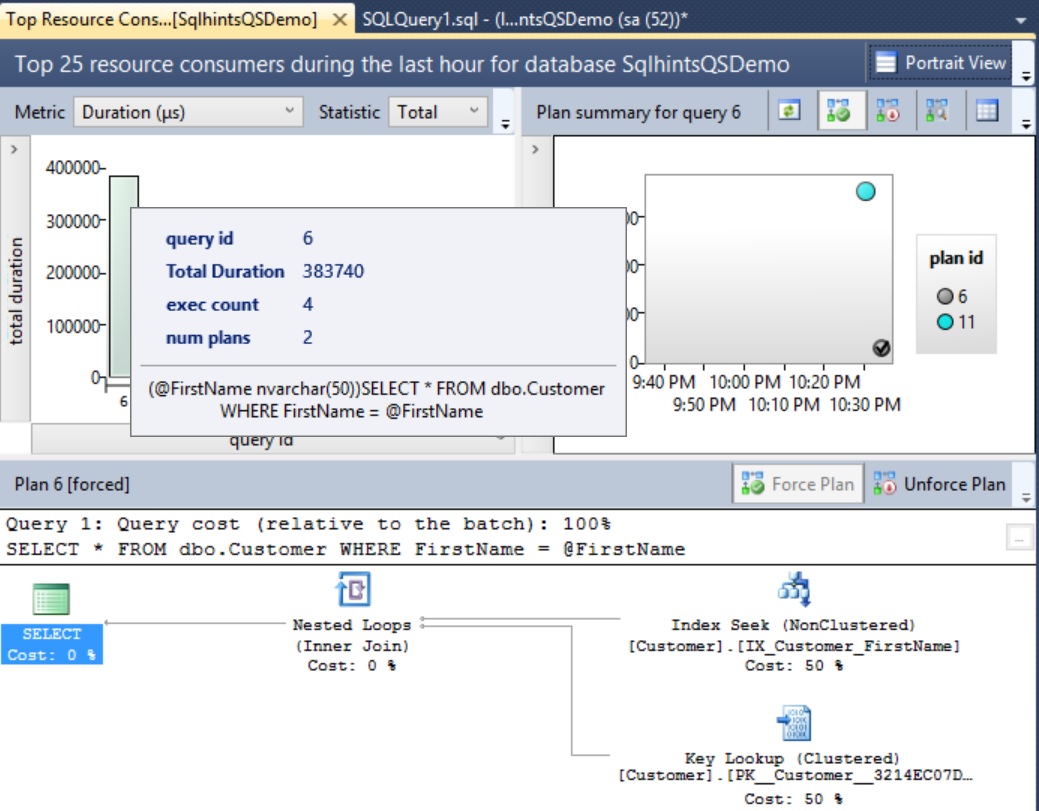
In this article, I will explain you on How to get an Index’s Root Page, Intermediate Pages and Leaf Pages Information. Prior to that let us get some insights into the Index structure.
In Sql Server an index is made up of a set of pages (index nodes) that are organized in a B+ tree structure. This structure is hierarchical in nature. The top node is called the ROOT node (Root Page). The bottom level of nodes in the index are called the leaf nodes (leaf Pages). Any index levels between the root and the leaf nodes are collectively known as intermediate levels. In a clustered index, the leaf nodes contain the data pages of the underlying table. The root and intermediate level nodes contain index pages holding index rows. Each index row contains a key value and a pointer to either an intermediate level page in the B-tree, or a data row in the leaf level of the index. The pages in each level of the index are linked in a doubly-linked list. In case of Clustered Index, data in a table is stored in a sorted order by the Clustered Index key Column. As a result, there can be only one clustered index on a table or view. In addition, data in a table is sorted only if a clustered index has been defined on a table.
Non-Clustered Index structure is similar to that of a B+ Tree Structure of Clustered Index, but the leaf nodes of a Non-Clustered index contain only the values from the indexed columns and row locators that point to the actual data rows, rather than contain the data rows themselves. Because of this in case of Non-Clustered Index, Sql Server takes additional steps to locate the actual data. The row locators structure depends on whether underlying table is a clustered table (Table with Clustered Index) or a heap table (Table without Clustered Index). In case the underlying table is a Clustered table the row locator points to the Clustered Index key value corresponding to the Non-Clustered Key and it is used to look-up into the Clustered Index to navigate to the actual data row. If underlying table is a heap table, the row locator points to the actual data row address. In case of Non-Clustered Index, the data rows of the underlying table are not sorted and stored in order based on their Non-Clustered keys.
B+ Tree Structure of a Clustered Index
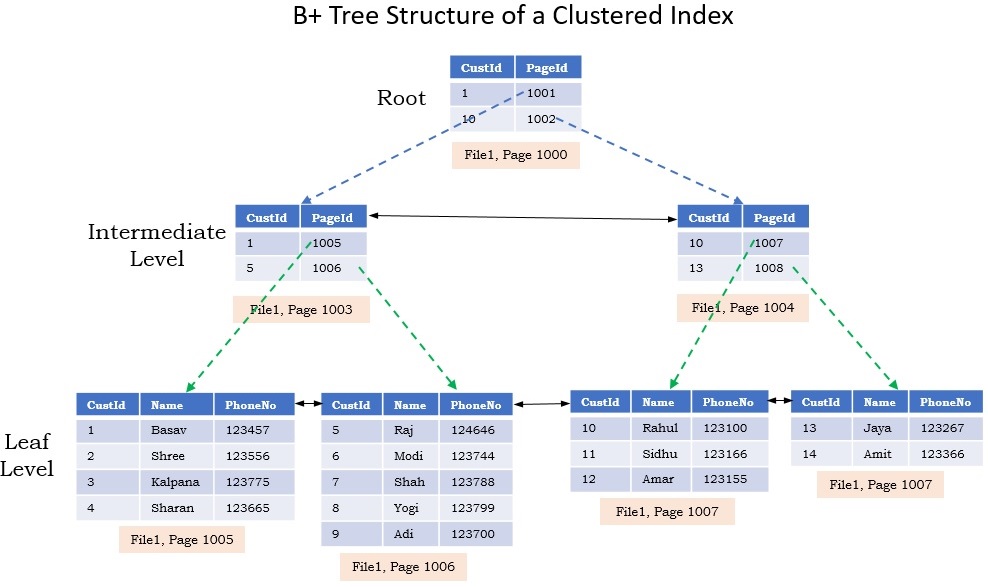
Let us explain how to get an Index’s Root Page, Intermediate Pages and Leaf Pages Information with an example
To explain how to get an Index’s Root Page, Intermediate Pages and Leaf Pages Information, let us create a Customer table as shown in the below image with 35K records. Execute the following script to Create the Customer Table with Clustered Index on the CustomerId column with sample 35K records.

--Create Demo Database
CREATE DATABASE SqlHints101PerfTips4
GO
USE SqlHints101PerfTips4
GO
--Create Demo Table Customers
CREATE TABLE dbo.Customers (
CustomerId INT IDENTITY(1,1) NOT NULL,
FirstName VARCHAR(50), LastName VARCHAR(50),
PhoneNumber VARCHAR(10), EmailAddress VARCHAR(50),
CreationDate DATETIME
)
GO
--Populate 35K dummy customer records
INSERT INTO dbo.Customers (FirstName, LastName, PhoneNumber, EmailAddress, CreationDate)
SELECT TOP 35000 REPLACE(NEWID(),'-',''), REPLACE(NEWID(),'-',''),
CAST( CAST(ROUND(RAND(CHECKSUM(NEWID()))*1000000000+4000000000,0) AS BIGINT) AS VARCHAR(10)),
REPLACE(NEWID(),'-','') + '@gmail.com',
DATEADD(HOUR,CAST(RAND(CHECKSUM(NEWID())) * 19999 as INT) + 1 ,'2006-01-01')
FROM sys.all_columns c1
CROSS JOIN sys.all_columns c2
GO
--Create a PK and a Clustered Index on CustomerId column
ALTER TABLE dbo.Customers
ADD CONSTRAINT PK_Customers_CustomerId
PRIMARY KEY CLUSTERED (CustomerId)
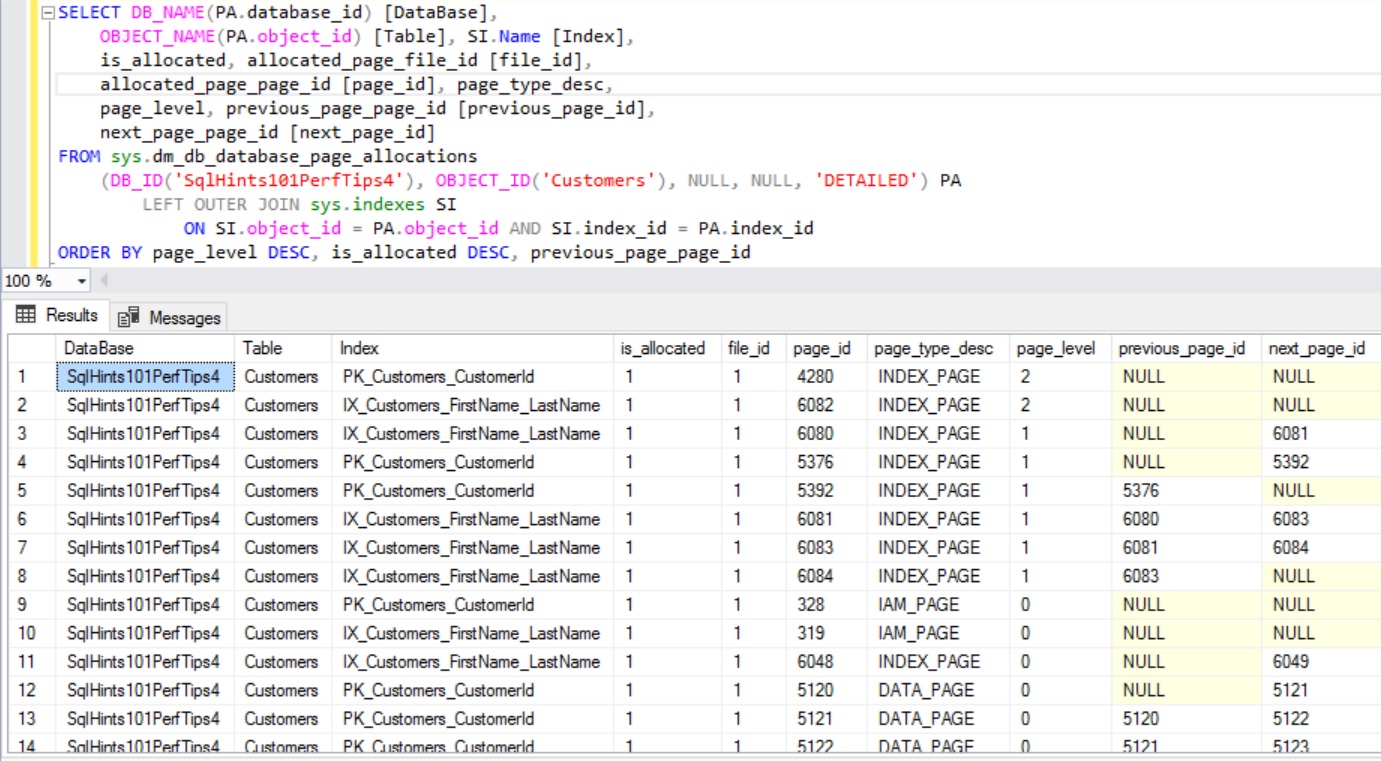
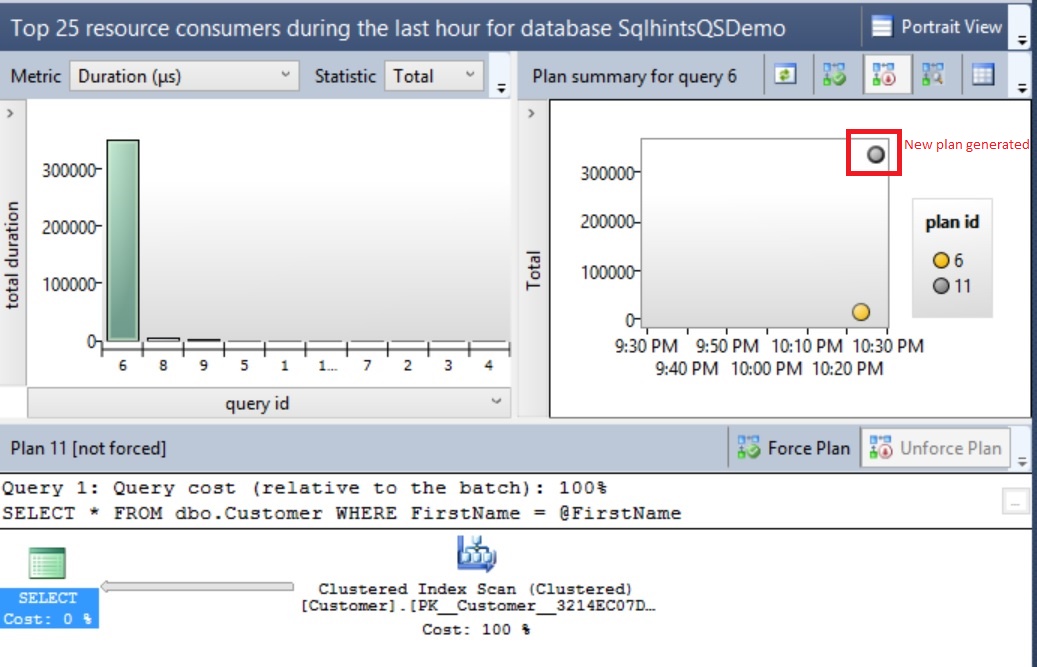
As explained in the previous article we can use Dynamic Management Function sys.dm_db_database_page_allocations to get the list of all the pages associated with an Index. Note sys.dm_db_database_page_allocations is an un-documented (i.e. feature that may change or removed without any notice or may produce un-expected result) DMF. So avoid using it in the Production environment.
Get all the Pages Associated with the Clustered Index PK_Customers_CustomerId
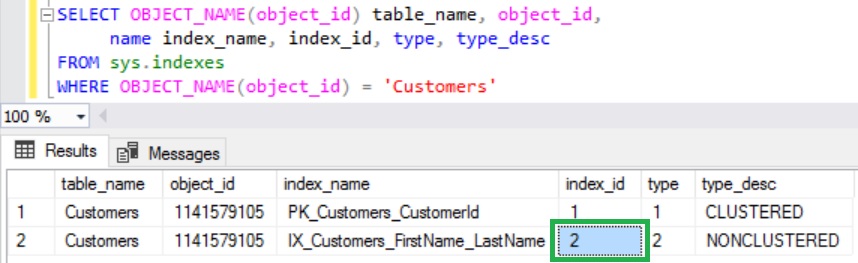
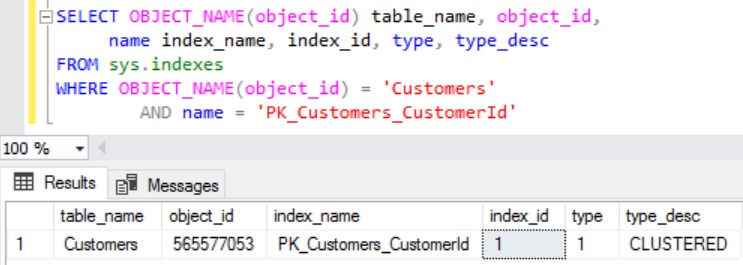
To get all the Pages associated with the Index PK_Customers_CustomerId of the Customers table, we need to pass the @DatabaseId, @TableId, @IndexId and @Mode Parameter values of the DMF sys.dm_db_database_page_allocations. We can use sys.indexes catalog view as shown below to get the Index Id for a Index.
SELECT OBJECT_NAME(object_id) table_name, object_id,
name index_name, index_id, type, type_desc
FROM sys.indexes
WHERE OBJECT_NAME(object_id) = 'Customers'
AND name = 'PK_Customers_CustomerId'
RESULT:
As explained in the previous article:
- Clustered Index will always will have the Index Id as 1.
- Index Id for the Non-Clustered Index will be >=2.
- Index Id for the Heap Table is 0.
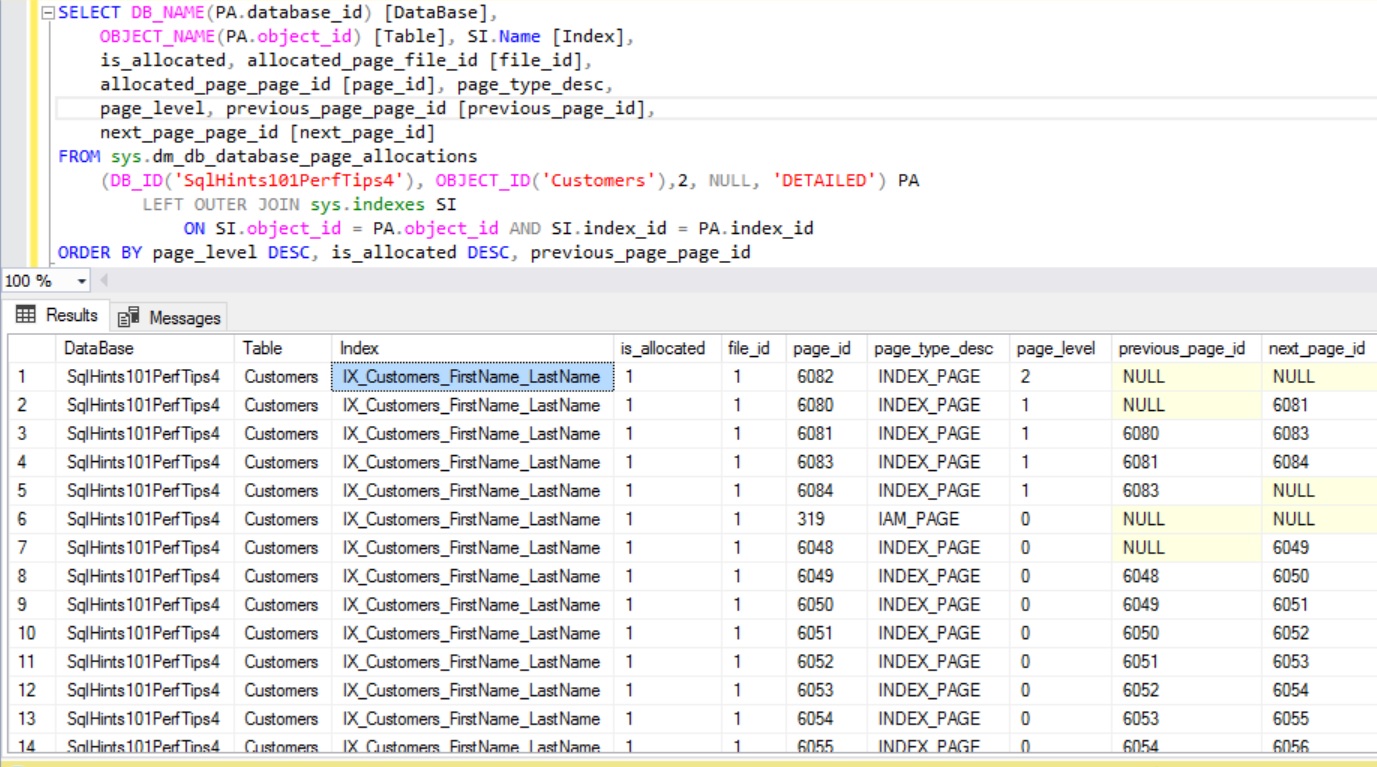
We can execute the below query to get all the pages associated with the Clustered Index PK_Customers_CustomerId
SELECT DB_NAME(PA.database_id) [DataBase],
OBJECT_NAME(PA.object_id) [Table], SI.Name [Index],
is_allocated, allocated_page_file_id [file_id],
allocated_page_page_id [page_id], page_type_desc,
page_level, previous_page_page_id [previous_page_id],
next_page_page_id [next_page_id]
FROM sys.dm_db_database_page_allocations
(DB_ID('SqlHints101PerfTips5'),
OBJECT_ID('Customers'), 1, NULL, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id
AND SI.index_id = PA.index_id
WHERE is_allocated = 1
and page_type in (1,2) -- INDEX_PAGE and DATA_PAGE Only
ORDER BY page_level DESC, is_allocated DESC,
previous_page_page_id
RESULT:
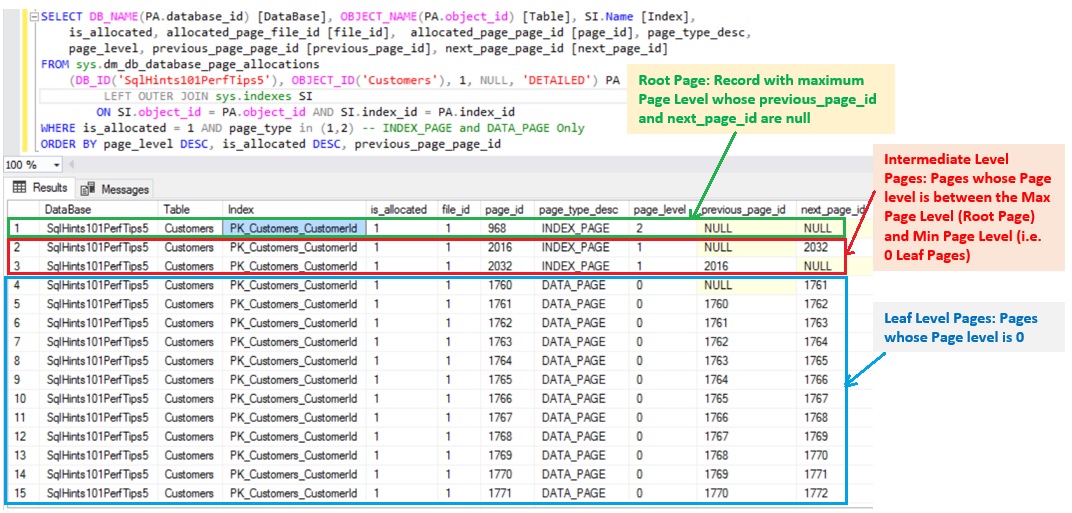
As shown in the above image the Root Page File Id is 1 and Page Id is 968. Root Page is the one with maximum Page_level (here in this example it is 2) having previous_page_id and next_page_id as NULL. Intermediate Pages File Id is 1 and Page Id’s are: 2016 and 2032. Intermediate pages are the one whose Page_Level is less than the root page level and greater than 0 (i.e. Leaf Page Level (i.e. 0) < Intermediate Page level (here it is 1) < Root Page level (here it is 2)). And leaf level pages are the the ones whose page level is 0.
We can use the below function to get the pages of the different levels of a B+ Tree Index:
We can use the below function to get the B+ Tree Clustered/Non-Clustered Index Root Page, Intermediate Level Pages and Leaf Level Pages. Note I am using sys.dm_db_database_page_allocations un-documented (i.e. feature that may change or removed without any notice or may produce un-expected result) DMF. So avoid using it in the Production environment.
CREATE FUNCTION dbo.GetPagesOfBPlusTreeLevel(
@DBName VARCHAR(100), @TableName VARCHAR(100) = NULL, @IndexName VARCHAR(100) = NULL,
@PartionId INT = NULL, @MODE VARCHAR(20), @BPlusTreeLevel VARCHAR(20)
)
RETURNS
@IndexPageInformation TABLE (
[DataBase] VARCHAR(100), [Table] VARCHAR(100), [Index] VARCHAR(100),
[partition_id] INT, [file_id] INT, [page_id] INT, page_type_desc VARCHAR(100),
page_level INT, [previous_page_id] INT, [next_page_id] INT)
AS
BEGIN
DECLARE @MinPageLevelId INT = 0 , @MaxPageLevelId INT = 0, @IndexId INT = NULL
SELECT @IndexId = index_id
FROM sys.indexes
WHERE OBJECT_NAME(object_id) = @TableName AND name = @IndexName
IF @IndexId IS NULL
RETURN
IF @BPlusTreeLevel IN ('Root', 'Intermediate')
BEGIN
SELECT @MaxPageLevelId = (CASE WHEN @BPlusTreeLevel ='Intermediate' THEN MAX(page_level) - 1 ELSE MAX(page_level) END),
@MinPageLevelId = (CASE WHEN @BPlusTreeLevel ='Intermediate' THEN 1 ELSE MAX(page_level) END)
FROM sys.dm_db_database_page_allocations
(DB_ID(@DBName), OBJECT_ID(@TableName), @IndexId, @PartionId, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id AND SI.index_id = PA.index_id
WHERE is_allocated = 1 AND page_type in (1,2) -- INDEX_PAGE and DATA_PAGE Only
IF @MaxPageLevelId IS NULL OR @MaxPageLevelId = 0
RETURN
END
INSERT INTO @IndexPageInformation
SELECT DB_NAME(PA.database_id) [DataBase], OBJECT_NAME(PA.object_id) [Table], SI.Name [Index],
[partition_id], allocated_page_file_id [file_id], allocated_page_page_id [page_id], page_type_desc,
page_level, previous_page_page_id [previous_page_id], next_page_page_id [next_page_id]
FROM sys.dm_db_database_page_allocations
(DB_ID(@DBName), OBJECT_ID(@TableName), @IndexId, @PartionId, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id AND SI.index_id = PA.index_id
WHERE is_allocated = 1 AND page_type in (1,2) -- INDEX_PAGE and DATA_PAGE Only
AND page_level between @MinPageLevelId AND @MaxPageLevelId
ORDER BY page_level DESC, previous_page_page_id
RETURN
END
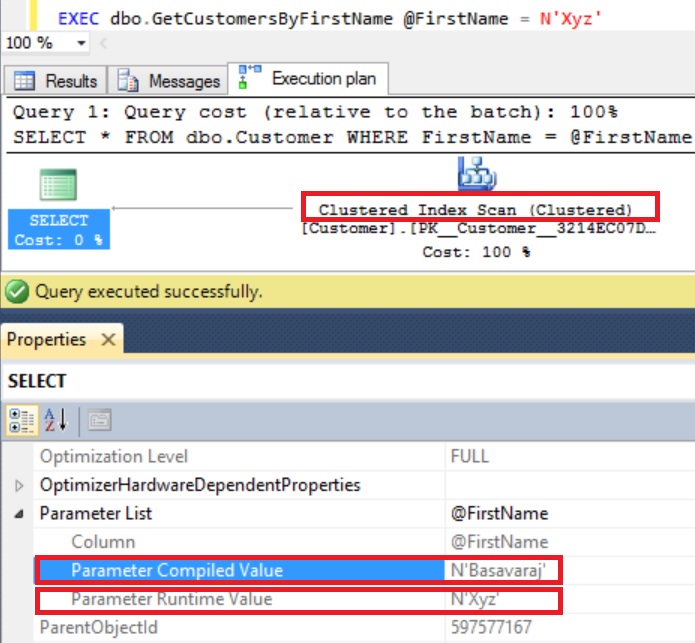
How to get an Index’s Root Page Information?
We can use the above function like below to get the root page of the Clustered Index PK_Customers_CustomerId on the Customers Table in the SqlHints101PerfTips5 Database.
SELECT *
FROM dbo.GetPagesOfBPlusTreeLevel
('SqlHints101PerfTips5', 'Customers',
'PK_Customers_CustomerId', NULL, 'DETAILED', 'Root')
RESULT:

There will be always on Root Page. Root Page is the one with maximum Page_level having previous_page_id and next_page_id as NULL. If the number of records in the table are very less and just one page is enough to store it. Then Sql Server doesn’t create the B+ Tree structure. So, in such scenario, the above function will not return the Root Page information.
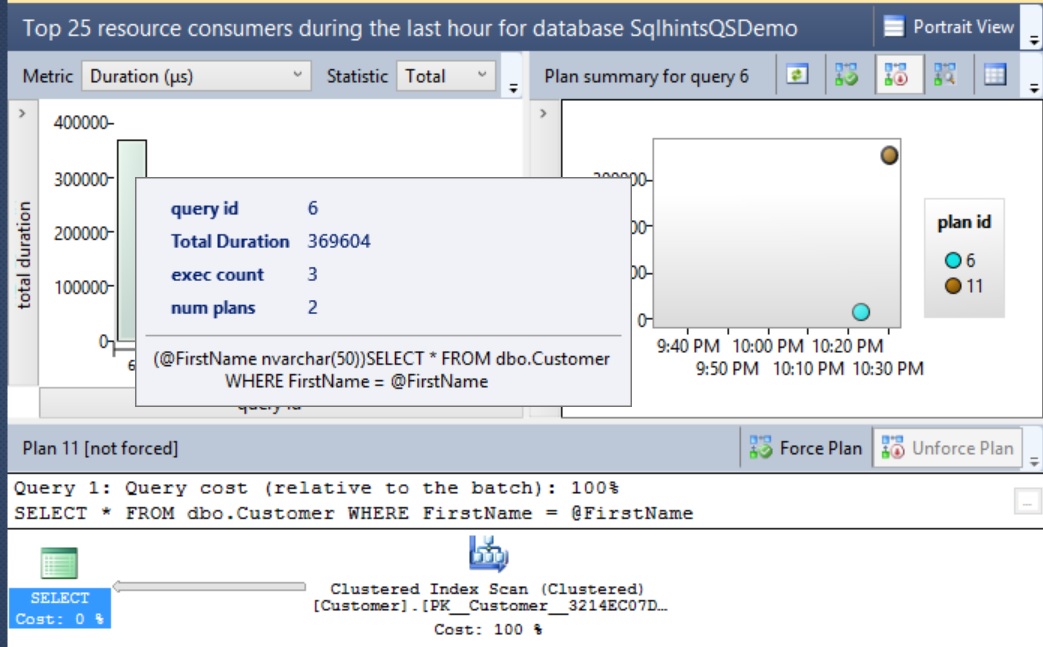
How to get an Index’s Intermediate Pages Information?
We can use the above function like below to get the Index’s Intermediate pages of the Clustered Index PK_Customers_CustomerId on the Customers Table in the SqlHints101PerfTips5 Database.
SELECT *
FROM dbo.GetPagesOfBPlusTreeLevel
('SqlHints101PerfTips5', 'Customers',
'PK_Customers_CustomerId', NULL, 'DETAILED', 'Intermediate')
RESULT:

Intermediate pages are the one whose Page_Level is less than the root page level and greater than Leaf Page Level (i.e. 0) (i.e. Leaf Page Level < Intermediate Page level < Root Page level). In the following situations an Index will not have intermediate pages: 1) If the number of records in the table are very less and just one page is enough to store it. Then Sql Server doesn't create the B+ Tree structure. 2) If the number records stored in the table are very less and it is spanning only couple of pages in such scenario Sql Server can have B+ Tree Index with just Root Page and the Leaf Level Pages. In such scenarios this function will not return any information. If we have a very large Table, then we can multiple Intermediate Levels.
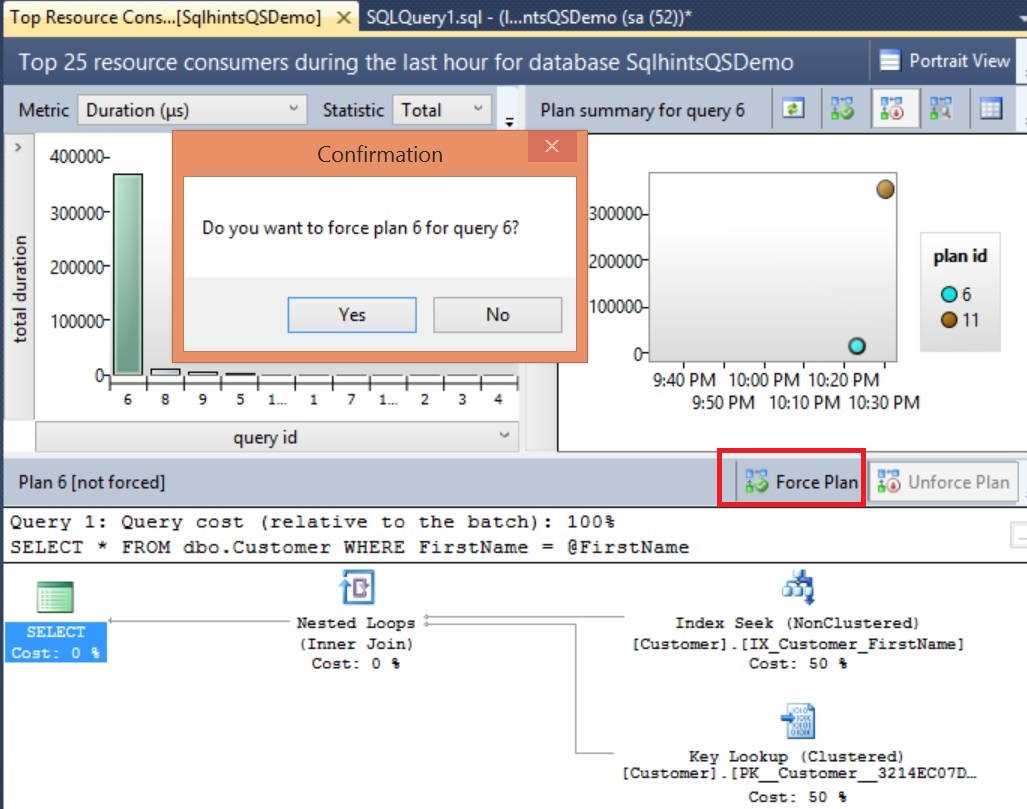
How to get an Index’s Leaf Page Information?
We can use the above function like below to get the Index’s Leaf pages of the Clustered Index PK_Customers_CustomerId on the Customers Table in the SqlHints101PerfTips5 Database.
SELECT *
FROM dbo.GetPagesOfBPlusTreeLevel
('SqlHints101PerfTips5', 'Customers',
'PK_Customers_CustomerId', NULL, 'DETAILED', 'Leaf')
RESULT:
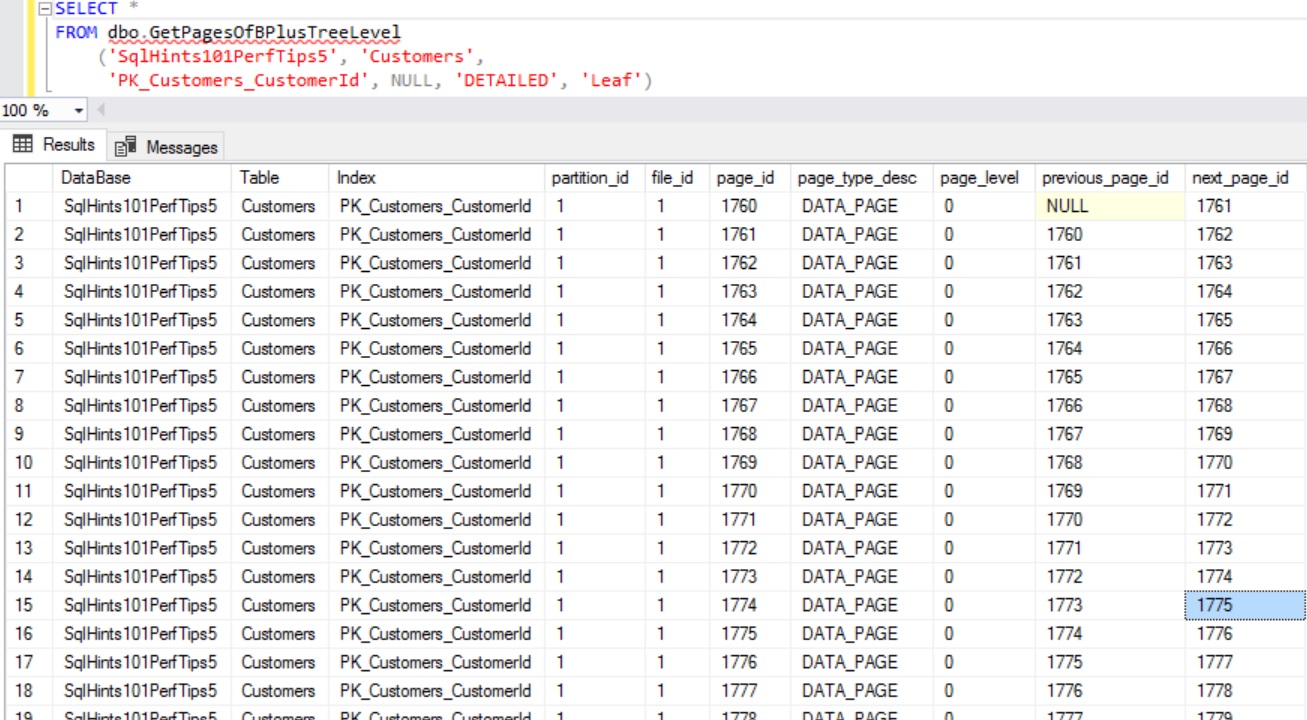
In case of Clustered Index the Page_Type_Desc of Leaf Pages is DATA_PAGE where as in case of Non-Clustered Index it will be INDEX_PAGE.
In the Next Article I will explain how we can use the DBCC PAGE command to look into what actually Sql Server stores in the Page.