sp_depends System Stored procedure will give the list of referencing entities for a table/view and list of referenced entities by the stored procedure/view/function. As per MSDN this system stored procedure is going to be removed from the future versions of the Sql Server.
sp_depends results are not always reliable/accurate/correct. Good and reliable alternative for sp_depends are the DMV’s: sys.dm_sql_referencing_entities and sys.dm_sql_referenced_entities.
Let us see this with an example the incorrect results returned by the sp_depends system stored procedure:
CREATE DATABASE DemoSQLHints
GO
USE DemoSQLHints
GO
CREATE PROCEDURE dbo.GetEmployeeDetails
AS
BEGIN
SELECT * FROM dbo.Employee
END
GO
CREATE TABLE dbo.Employee
(Id int IDENTITY(1,1), FirstName NVarchar(50), LastName NVarchar(50))
GO
INSERT INTO dbo.Employee(FirstName, LastName)
VALUES('BASAVARAJ','BIRADAR')
GO
-- Get the list of objects which are referring Employee table using
sp_depends [dbo.Employee]
GO
-- Get the list of objects referenced by the SP:GetEmployeeDetails
sp_depends [dbo.GetEmployeeDetails]
GO
Result
Object does not reference any object, and no objects reference it. Object does not reference any object, and no objects reference it.
Both the sp_depends statements in the above script are not returning the referencing/referenced objects list. For example the stored procedure dbo.GetEmployeeDetails is referring the Employee table but sp_dpends is not providing this dependency information. Reason for this is: Stored procedure dbo.GetEmployeeDetails which is refereeing to this Employee table is created first and then the employee table in other words we call it as deferred resolution.
Solution to this problem is to use the DMV’s: sys.dm_sql_referencing_entities and sys.dm_sql_referenced_entities. Now let us check whether we are able to get the expected results using these DMV’s:
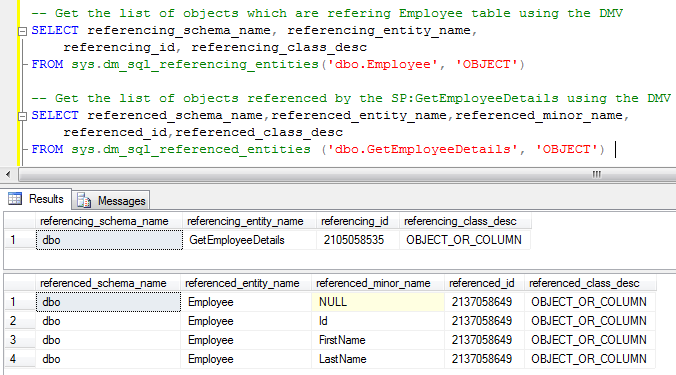
Note: These two DMV’s are introduced as a part of Sql Server 2008. So this alternate solution works for Sql Server version 2008 and above.
You may also like to read my other article: How to Insert Stored Procedure result into a table in Sql Server?
Please correct me if my understanding is not correct. Comments are always welcome.