How to Inspect the content of a DATA PAGE or INDEX PAGE ? Tip 6: Sql Server 101 Performance Tuning Tips and Tricks
In the previous articles “How to find the list of all Pages that belongs to a Table and Index?” and “How to get an Index’s Root Page, Intermediate Pages and Leaf Pages Information?” I have explained how to get the pages of a Table/Index. In this Article I will explain how we can inspect the content of these Pages (i.e. DATA PAGE or INDEX PAGE).
We can use the DBCC PAGE command to look into the content of any page in Sql Server. DBCC PAGE command is an Sql Server un-documented (i.e. feature that may change or removed without any notice or may produce un-expected result. So avoid using it in the Production environment.) feature.
Before we look into the DBCC PAGE command, let us look into the Sql Server Page Structure
In Sql Server Each Page size is 8KB. A page is tied to single object, it can’t be shared. In each page 96 bytes is reserved for the Page Header information and remaining 8096 bytes is Page Body which actually contains the Table/Index data. Page will also have a row offset array (Page Slot Array). The slot array is a list of 2 byte pointers to the beginning of each row. So if there are two rows in the table then this array will have two items in it and each one pointing to the beginning of their corresponding row. For clustered Index common assumption is that, data is stored physically in the sorted order as per the clustered index key column value. This is partially correct, because across the pages the records are sorted in a sorted order as per Clustered Index Key Column value but within a data page the data is not stored in a sorted order, instead the slot array is used to maintain the sorting of the records. When we insert a new record as per the sorting order it is inserted into the correct data page, but within data page it is just appended at the end of the last record. But actually the slot array maintains the sorting order by pointing to the rows as per the index columns sorted value. For example as shown in the below image, the row offset array’s first element is pointing to the second row in the data page where as the second slot array item is pointing to the first row stored on the page, because as per the index column value sorted order of second row comes first and first row comes second. Sql Server fetches the records from the Data Page as per the order of the rows pointed by the Slot Array pointers. So, records on the page are not sorted but the slot array values are stored in the sorted order as per the Clustered Index Key Column value.
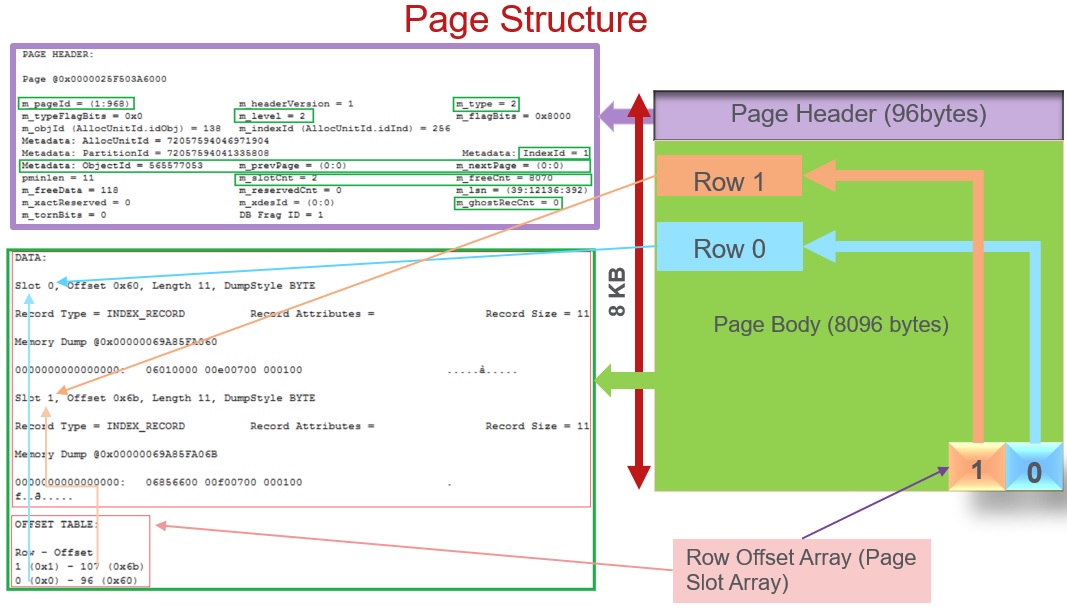
Some of the important attributes which are maintained in the Page Header are highlighted in the above Sql Server Page Structure and below is the description of it. The above image is the also shows the content of the Clustered Index Root Page:
- m_pageId = (1:968) : This is the id of the page which we are inspecting. In Sql Server Pages it is stored as FileId:PageId. Here 1 is FileId and 968 is the PageId
- m_type = 2 Here m_type value 2 means it is an Index Page, where as value 1 means it is a Data Page and value 10 means it is an IAM page.
- m_level = 2 This indicates the level of the page. For example it’s value 0 means it is an leaf level page, page with maximum m_level value with Previous and Next Page id value as NULL (i.e. (0:0)) means it is an Root Page. And pages whose m_level value in-between leaf page and root page m_level values are called intermediate pages. For more details on the Index Structure you can refer to the previous article.
- m_prevPage = (0:0) It is the id of the previous page to the current page. Here (0:0) means there are no previous page for this page.
- m_nextPage = (0:0) It is the id of the next page to the current page. Here (0:0) means there are no next page for this page.
- m_slotCnt = 2 This attribute tells that there are two row offset array (i.e. Page Slot Array) elements pointing to two rows on the page.
- m_freeCnt = 8070 This attribute tells the free available space on the page. In this case it is 8070 bytes.
- m_ghostRecCnt = 0 When we delete a record, Sql Server doesn’t delete the record on the page. Instead it marks the record as ghost record and removes the pointer to the row from the slot array. This attribute maintains the count of Such ghost records on the page, so that it can be used by the Ghost Clean Process to remove these records later.
Syntax of DBCC PAGE Command:
DBCC PAGE ({@DatabaseId|@DatabaseName}, @FileId, @PageId
[,@OutPutOption={0|1|2|3}]) [WITH TABLERESULTS]
Parameters:
- @DatabaseId|@DatabaseName : For the first parameter we can pass either the Database Id or Database Name.
- @FileId : Id of the file which contains the Page which we want to Inspect.
- @PageId : Id of the Page which we want to reflect.
- @OutPutOption : This option specifies that, what information to be returned in the output of the DBCC PAGE command. Following are the possible values for this parameter:
- 0-Returns the page header
- 1-Returns the Page header, per row hex dump and Row Offset Array (i.e. page slot array).
- 2-Returns the Page header and whole page hex dump
- 3-Returns the Page header, per row hex dump and detailed per row explanation.
- WITH TABLERESULTS: This clause is optional, this returns the output in tabular format. Without this option by default you will not be able to see the output of this DBCC command. This is because by default Sql Server sends the DBCC PAGE command output to the errorlog. To get the output of this command without the WITH TABLERESULTS clause to the current connection SSMS window, you need to enable the Trace flag 3604 by executing the command: DBCC TRACEON (3604). We can turn off this Trace flag by executing the command DBCC TRACEOFF (3604).
To explain how we can use the DBCC PAGE command to look into the content of Data/Index Page, let us create a Customer table as shown in the below image with 35K records. Execute the following script to Create the Customer Table with Clustered Index on the CustomerId column with sample 35K records. Note this is the same database and table which is created in the previous article, if you already have this database no-need to re-create it.

--Create Demo Database
CREATE DATABASE SqlHints101PerfTips5
GO
USE SqlHints101PerfTips5
GO
--Create Demo Table Customers
CREATE TABLE dbo.Customers (
CustomerId INT IDENTITY(1,1) NOT NULL,
FirstName VARCHAR(50), LastName VARCHAR(50),
PhoneNumber VARCHAR(10), EmailAddress VARCHAR(50),
CreationDate DATETIME
)
GO
--Populate 35K dummy customer records
INSERT INTO dbo.Customers (FirstName, LastName, PhoneNumber, EmailAddress, CreationDate)
SELECT TOP 35000 REPLACE(NEWID(),'-',''), REPLACE(NEWID(),'-',''),
CAST( CAST(ROUND(RAND(CHECKSUM(NEWID()))*1000000000+4000000000,0) AS BIGINT) AS VARCHAR(10)),
REPLACE(NEWID(),'-','') + '@gmail.com',
DATEADD(HOUR,CAST(RAND(CHECKSUM(NEWID())) * 19999 as INT) + 1 ,'2006-01-01')
FROM sys.all_columns c1
CROSS JOIN sys.all_columns c2
GO
--Create a PK and a Clustered Index on CustomerId column
ALTER TABLE dbo.Customers
ADD CONSTRAINT PK_Customers_CustomerId
PRIMARY KEY CLUSTERED (CustomerId)
As explained in the previous article we can use Dynamic Management Function sys.dm_db_database_page_allocations to get the list of all the pages associated with a Table/Index. Note sys.dm_db_database_page_allocations is an un-documented (i.e. feature that may change or removed without any notice or may produce un-expected result) DMF. So avoid using it in the Production environment.
Get all the Pages Associated with the Clustered Index PK_Customers_CustomerId
To get all the Pages associated with the Index PK_Customers_CustomerId of the Customers table, we need to pass the @DatabaseId, @TableId, @IndexId and @Mode Parameter values of the DMF sys.dm_db_database_page_allocations. We can use sys.indexes catalog view as shown below to get the Index Id for a Index.
SELECT OBJECT_NAME(object_id) table_name, object_id,
name index_name, index_id, type, type_desc
FROM sys.indexes
WHERE OBJECT_NAME(object_id) = 'Customers'
AND name = 'PK_Customers_CustomerId'
RESULT:
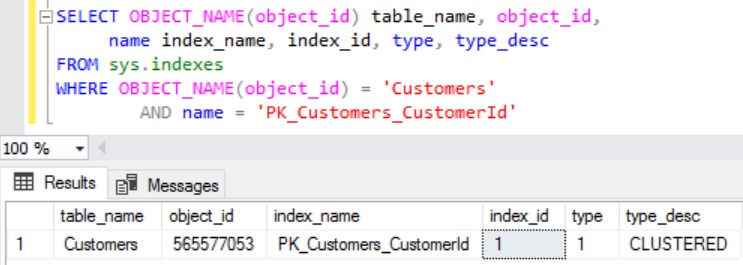
As explained in the previous article:
- Clustered Index will always will have the Index Id as 1.
- Index Id for the Non-Clustered Index will be >=2.
- Index Id for the Heap Table is 0.
We can execute the below query to get all the pages associated with the Clustered Index PK_Customers_CustomerId
SELECT DB_NAME(PA.database_id) [DataBase],
OBJECT_NAME(PA.object_id) [Table], SI.Name [Index],
is_allocated, allocated_page_file_id [file_id],
allocated_page_page_id [page_id], page_type_desc,
page_level, previous_page_page_id [previous_page_id],
next_page_page_id [next_page_id]
FROM sys.dm_db_database_page_allocations
(DB_ID('SqlHints101PerfTips5'),
OBJECT_ID('Customers'), 1, NULL, 'DETAILED') PA
LEFT OUTER JOIN sys.indexes SI
ON SI.object_id = PA.object_id
AND SI.index_id = PA.index_id
WHERE is_allocated = 1
and page_type in (1,2) -- INDEX_PAGE and DATA_PAGE Only
ORDER BY page_level DESC, is_allocated DESC,
previous_page_page_id
RESULT:
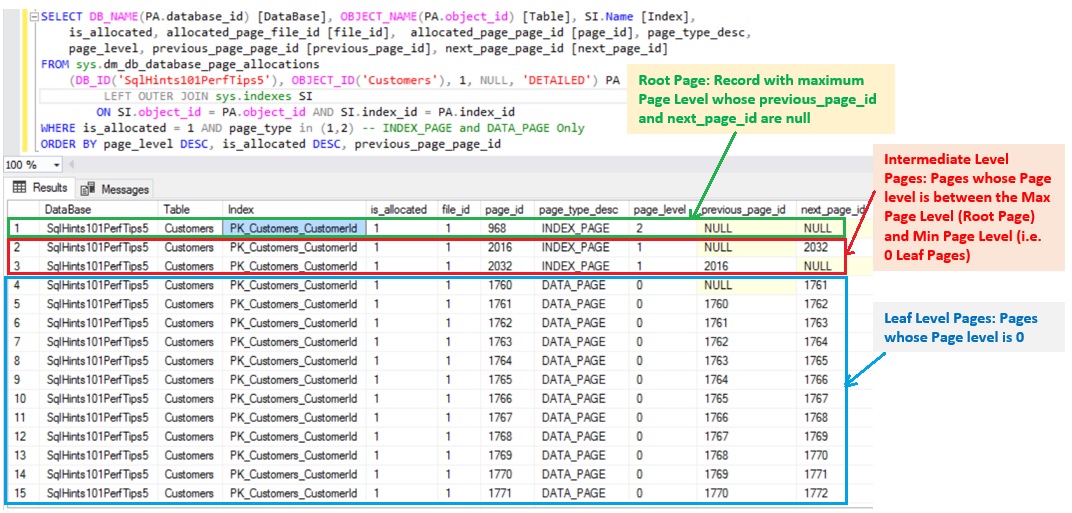
As shown in the above image the Root Page File Id is 1 and Page Id is 968. Root Page is the one with maximum Page_level (here in this example it is 2) having previous_page_id and next_page_id as NULL. Intermediate Pages File Id is 1 and Page Id’s are: 2016 and 2032. Intermediate pages are the one whose Page_Level is less than the root page level and greater than 0 (i.e. Leaf Page Level (i.e. 0) < Intermediate Page level (here it is 1) < Root Page level (here it is 2)). And leaf level pages are the the ones whose page level is 0, here the leaf level pages File Id is 1 and Page Id's are 1760, 1761, 1762, 1763, 1764 etc.
Example 1: Let us inspect the Clustered Index Root Page with File Id:1 and Page Id:968 using DBCC PAGE Command
DBCC PAGE ('SqlHints101PerfTips5',1,968,3) WITH TABLERESULTS
RESULT:
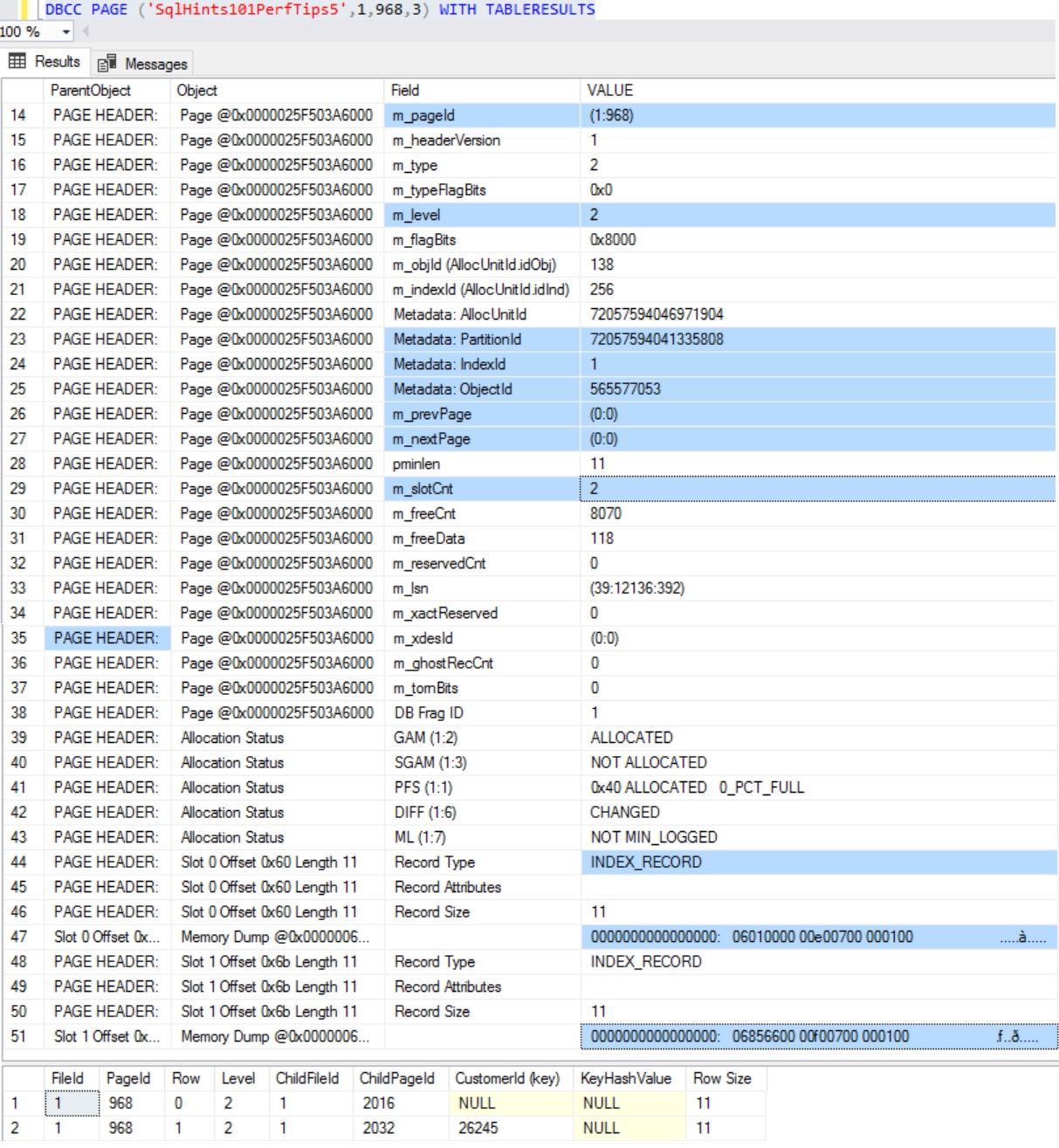
From the above result we can see that the Index Root Page has Page Header Information and hex dump of the two INDEX_RECORD. The second result set shows these two Index records. In this result set, we can see that Sql Server is storing Clustered Index Key Column CustomerId value and the Child Page Id. Here the first record’s CustomerId (i.e. Index Key) Column value is NULL and it’s Child Page Id is 2016 and Second Record’s CustomerId (i.e. Index key) column value is 26245 and it’s Child Page Id is 2032. As the m_level (i.e. Page level) of this clustered index root page value is 2, it means the child page is an Index Intermediate page. It means the the Child Page 2016 contains the CustomerId records whose value is NULL <= CustomerId < 26244. And the child page id 2032 contains the CustomerId records whose value is 26245 <= Customer <= max(CustomerId)
Example 2: Let us inspect the Clustered Index Intermediate Page with File Id:1 and Page Id:2016 using DBCC PAGE Command
DBCC PAGE ('SqlHints101PerfTips5',1,2016,3) WITH TABLERESULTS
RESULT:
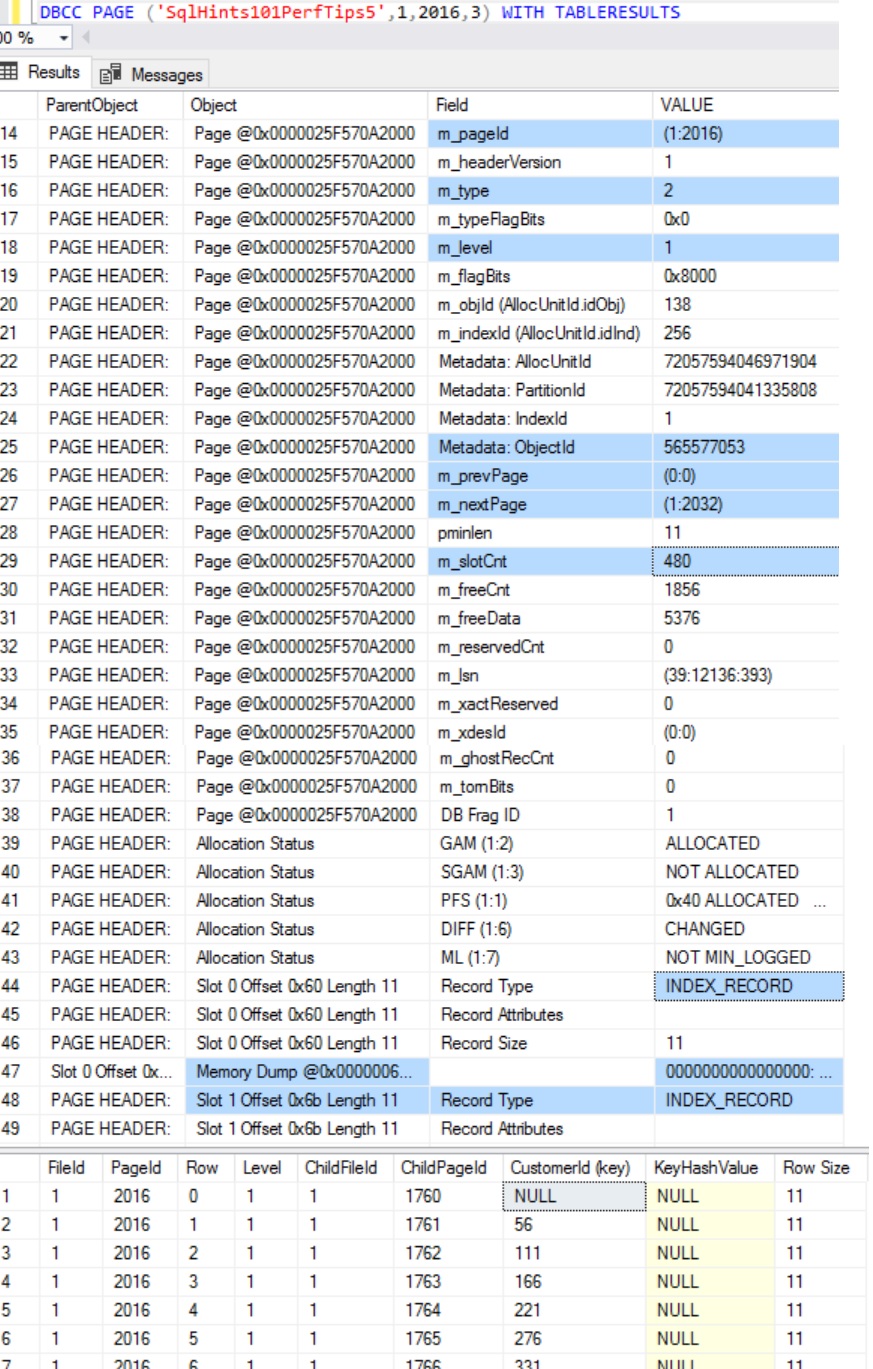
From the above result we can see that this Clustered Index’s Intermediate Page has Page Header Information and hex dump of INDEX_RECORD’s. Here the m_type is 2, it means it is an Index Page. m_level value is 1, it means the child page of this page will be a leaf page with m_level value as 0. And the leaf level page type will be data page, as it is a Clustered Index contains. Here the m_slotCnt is 480, it means there are 480 Index Records on this Intermediate Page pointing to 480 child leaf level Data Pages.
The second result set shows these 480 Index records. In this result set, we can see that Sql Server is storing Clustered Index Key Column CustomerId value and the Child Page Id. Here the first record’s CustomerId (i.e. Index Key) Column value is NULL and it’s Child Page Id is 1760. Second Record’s CustomerId (i.e. Index key) column value is 56 and it’s Child Page Id is 1761 and So On. It means the the Child Page 1760 contains the table records whose CustomerId value is NULL <= CustomerId < 56. Similarly, the child page id 1761 contains the table records whose CustomerId value is 56 <= CustomerId < 111 and so on.
Example 3: Let us inspect the Clustered Index Leaf Page (i.e. Data Page) with File Id:1 and Page Id:1760 using DBCC PAGE Command
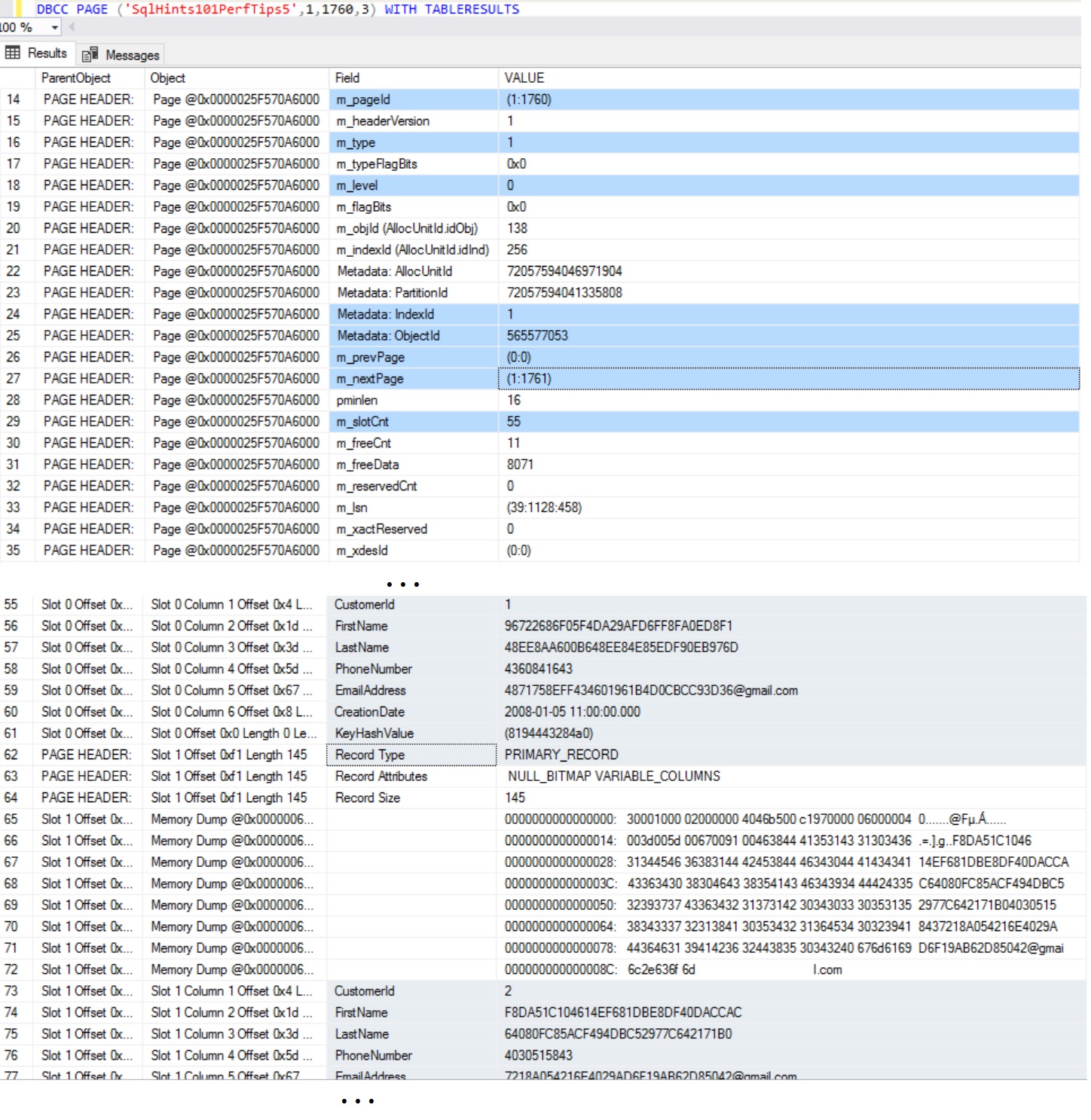
Page Header: m_type value as shown above is 1, it means it is a data page. m_level value as 0, means it is leaf level page. m_slotCnt is 55, it means this page has 55 records of the table. As it is the first leaf page, it doesn’t have a previous page, but it has a next page (1:1761). The pages are linked by doubly linked list, each page point’s to previous and next page in Sql Server.
Page Body: As shown above we can see the complete row values for the Customers table are stored in the page. So, the leaf pages of a Clustered Index contains the actual table data.