If you need your query to run faster, then you must know about the indexes. In this series of articles on Indexes, I will walk you through Sql Server Indexes with examples and explain how Sql Server Indexes come handy to resolve query performance issue. This series of articles will be helpful for both Sql beginners and advance users. I will try to keep this series of articles on Indexes as simple as possible by keeping in mind the beginner audience.
In this Part-I article of the series of articles on Sql Server Indexes, I will explain how to enable the execution plan, IO and Time statistics. It will also cover HEAP tables and problems while querying data from it.
The main purpose of Sql Server indexes is to facilitate the faster retrieval of the rows from a table. Sql Server indexes are similar to indexes at the end of the book whose purpose is to find a topic quickly.
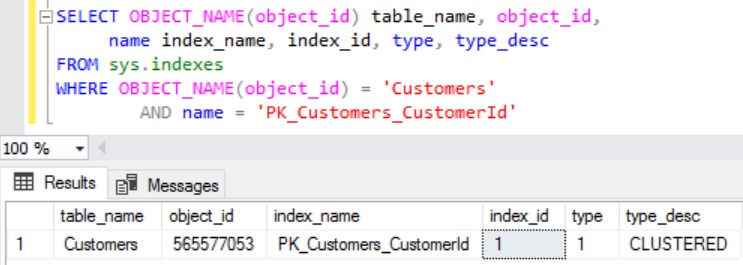
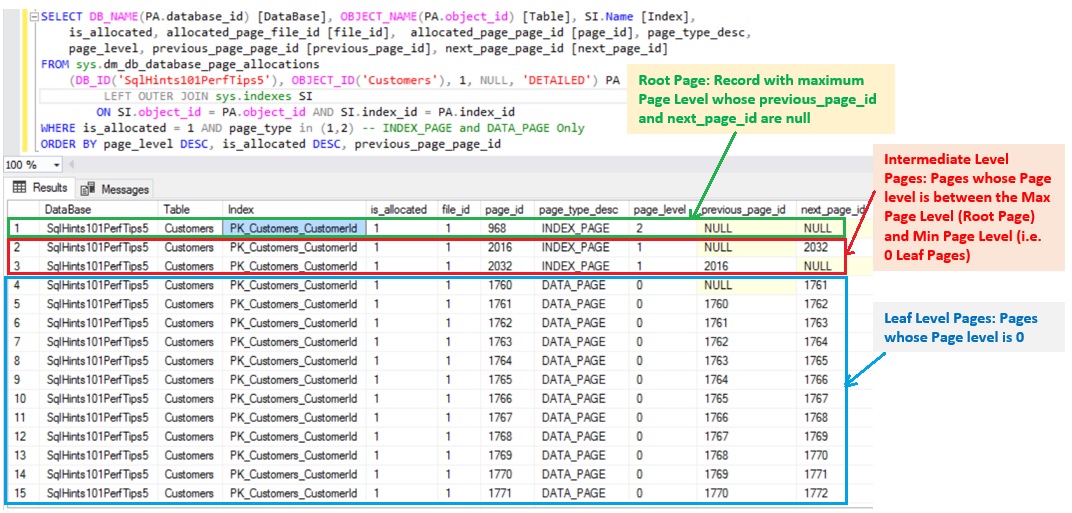
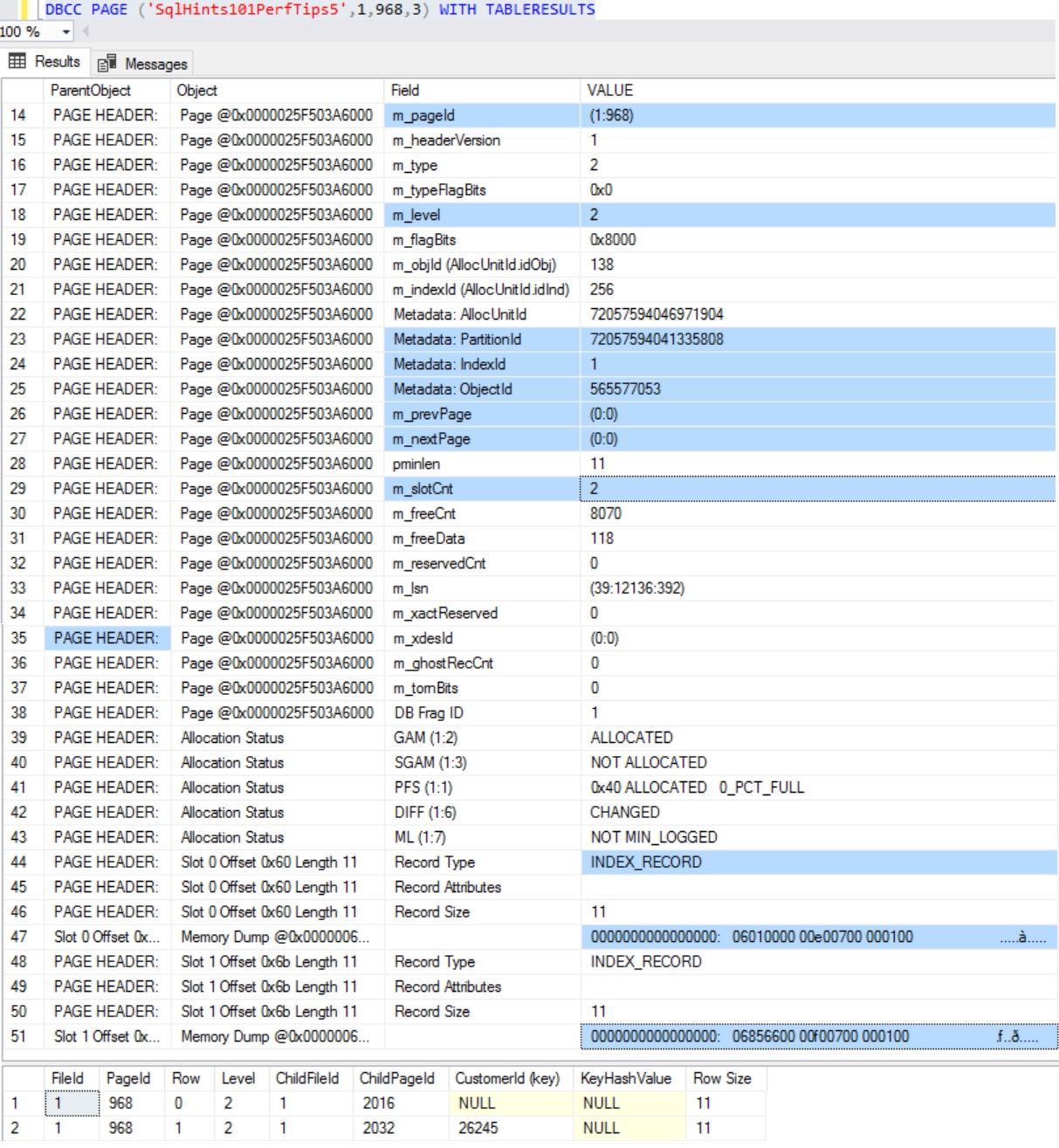
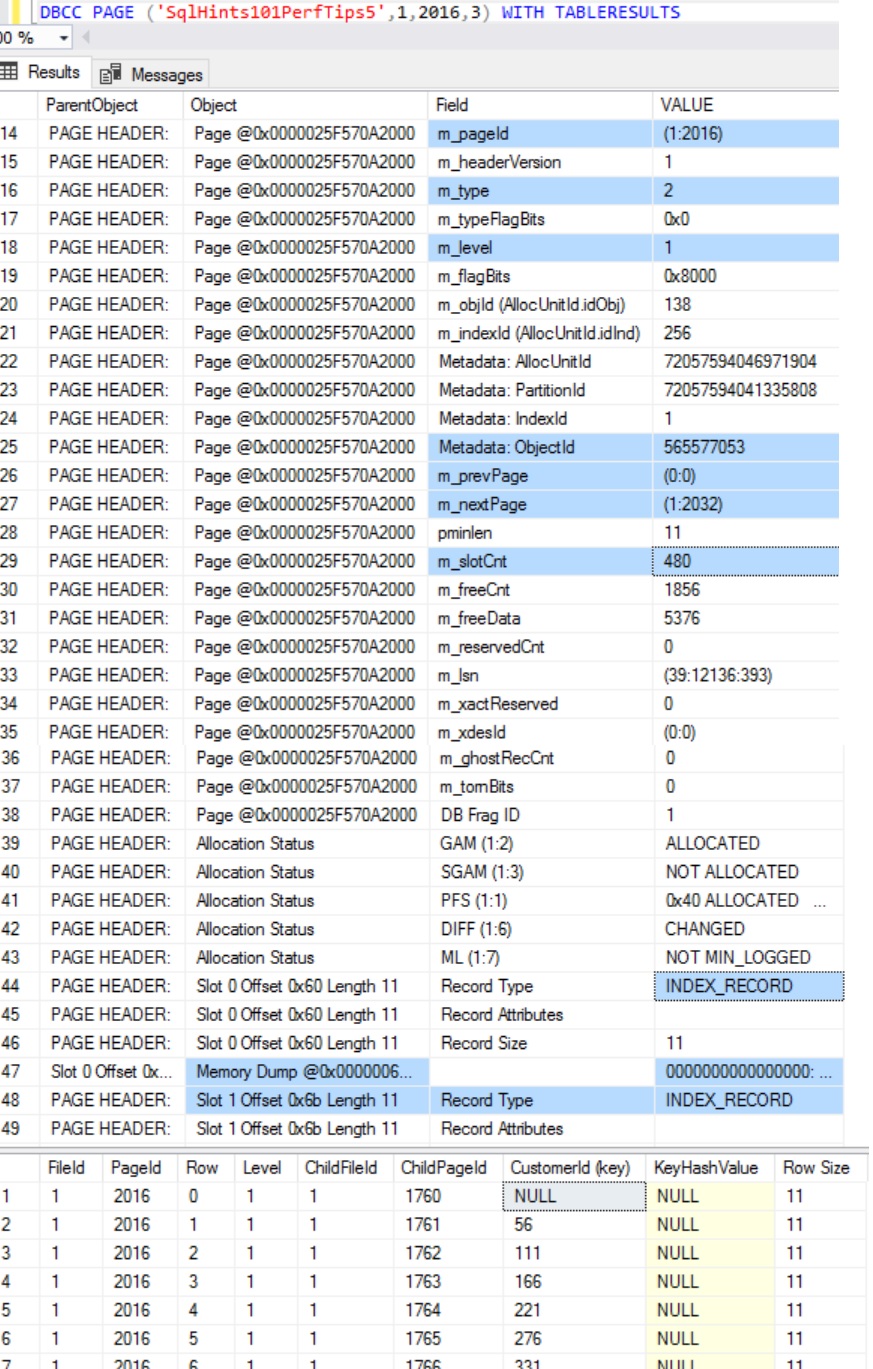
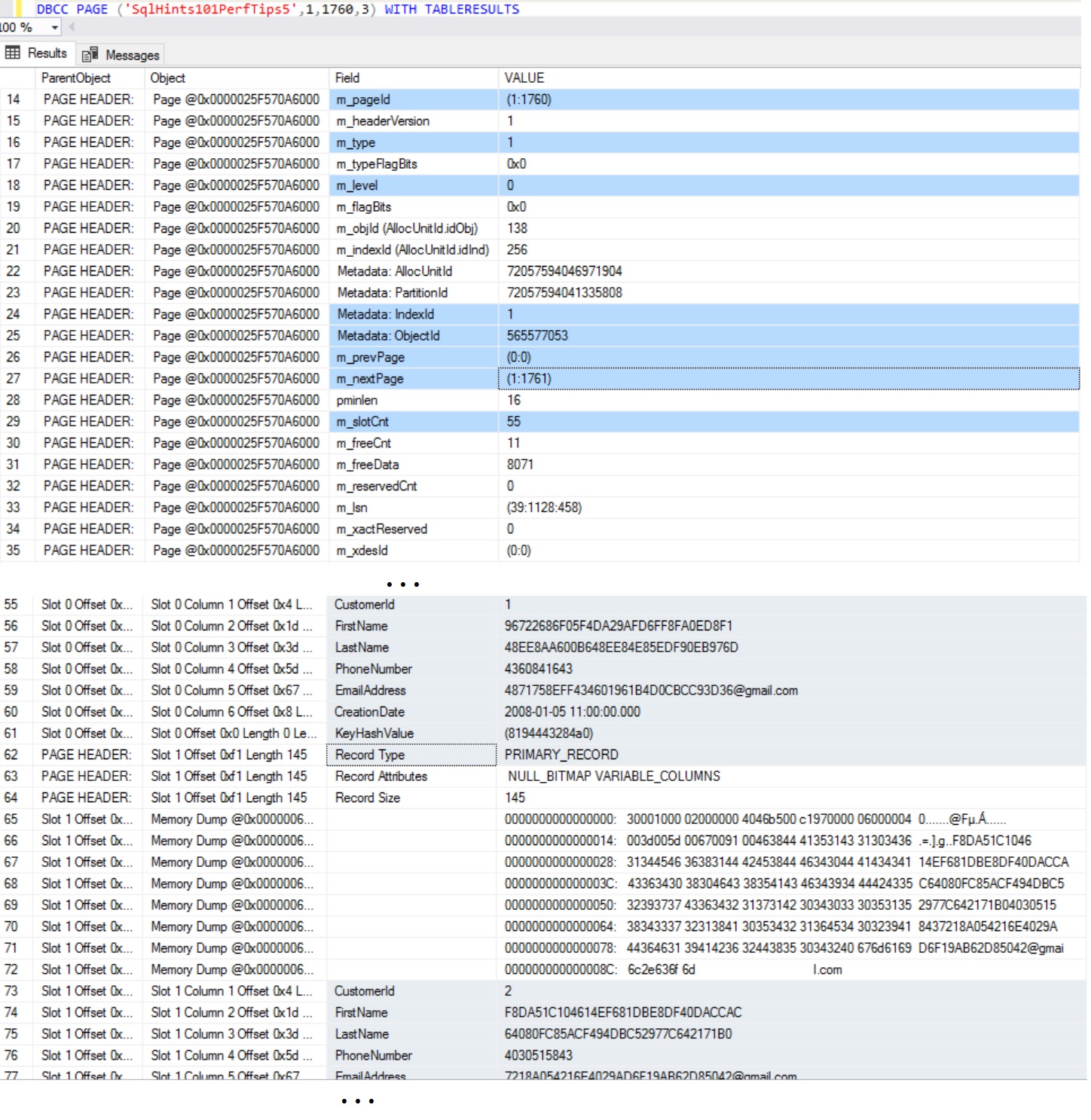
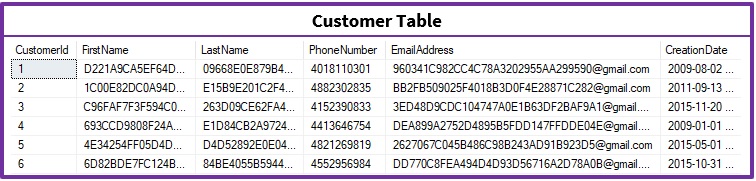
To understand Sql Server Indexes with example, let us create a Customer table as shown in the below image. Execute the following script to create the Customer table with sample 100,000 records.
--Create Demo Database
CREATE DATABASE SqlHintsIndexTutorial
GO
USE SqlHintsIndexTutorial
GO
--Create Demo Table Customer
CREATE TABLE dbo.Customer (
CustomerId INT IDENTITY(1,1) NOT NULL,
FirstName VARCHAR(50), LastName VARCHAR(50),
PhoneNumber VARCHAR(10), EmailAddress VARCHAR(50),
CreationDate DATETIME
)
GO
--Populate 1 million dummy customer records
INSERT INTO dbo.Customer (FirstName, LastName, PhoneNumber, EmailAddress, CreationDate)
SELECT TOP 1000000 REPLACE(NEWID(),'-','') FirstName, REPLACE(NEWID(),'-','') LastName,
CAST( CAST(ROUND(RAND(CHECKSUM(NEWID()))*1000000000+4000000000,0) AS BIGINT) AS VARCHAR(10))
PhoneNumber,
REPLACE(NEWID(),'-','') + '@gmail.com' EmailAddress,
DATEADD(DAY,CAST(RAND(CHECKSUM(NEWID())) * 3650 as INT) + 1 ,'2006-01-01') CreationDate
FROM sys.all_columns c1
CROSS JOIN sys.all_columns c2
GO
--Update one customer record with some know values
UPDATE dbo.Customer
SET FirstName = 'Basavaraj', LastName = 'Biradar',
PhoneNumber = '4545454545', EmailAddress = 'basav@sqlhints.com'
WHERE CustomerId = 50000
GO
Enable Execution Plan
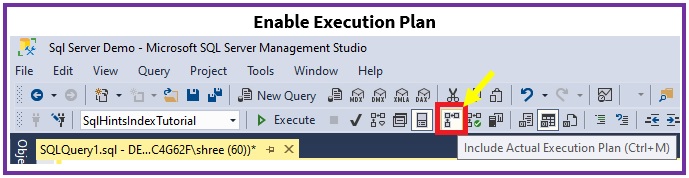
Enable the display of query execution plan in Sql Server Management Studio (SSMS) by clicking on the Actual Execution Plan option as shown in the below image. You can as well enable/disable the Actual Execution Plan by pressing the key stroke CTRL + M.
What is execution plan?
Beginners may be wondering what is this execution plan? In Sql Server execution plan is nothing but the visual representation of steps or operations which Sql Server performs internally to execute a query and return the result.
Enable the display of IO and Time Statistics for a Query
Execute the following statements to enable both IO and Time statistics in one statement.
SET STATISTICS IO,TIME ON
The SET STATISTICS IO ON statement displays the disk activity performed to execute the Sql query. In Sql Server table data is stored in 8 KB data pages on the disk. Whenever we try to read the data from a table, the Sql Server query engine first checks whether data page is already in memory. If the page is already in memory then sql uses that, this operation is shown as logical read in SET STATISTICS IO output of the query. If sql doesn’t find the data page in the memory then it reads it from the disk, this operation is shown as physical read in SET STATISTICS IO output of the query. Both logical and physical reads of a data page is a costly operation. A query should have minimal page reads. The SET STATISTICS TIME ON output of the query shows the time taken by the query to complete the execution. In the following sections, I will explain both these settings results with an example. It will be more clear once you go through the examples in the following sections.
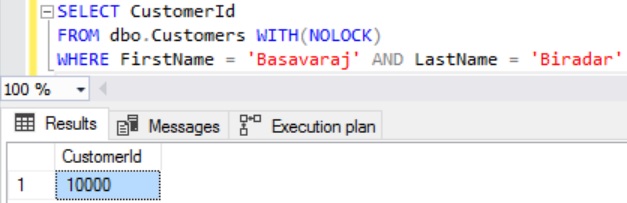
Execute the following query to get the details of a Customer whose CustomerId is 50000.
SELECT * FROM dbo.Customer WITH(NOLOCK) WHERE CustomerId = 50000
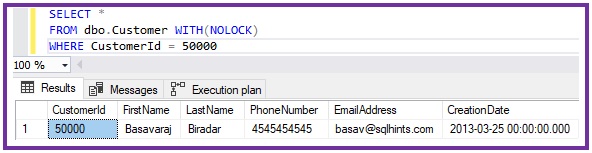
From the above result, we can see that we have one customer record in the Customer table with CustomerId as 50000.
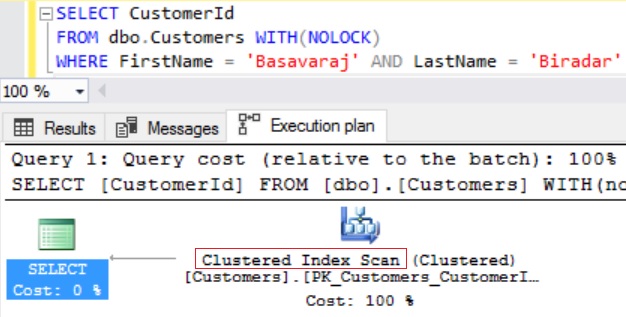
Let us now go to the Execution Plan tab of the result and see the execution plan of the query.
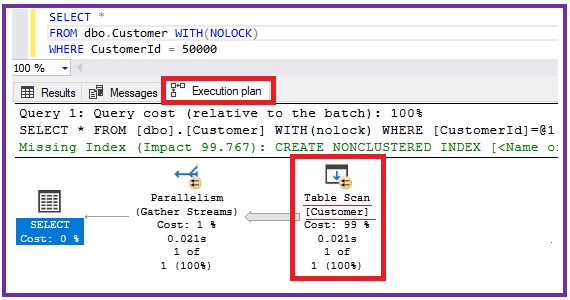
From the above execution plan we can see that Sql Server is doing the table scan of the Customer table. Table scan means Sql server is reading all the data pages and rows of the table to find the records in the customer table. Even after finding the first record with CustomerId = 50000, Sql server will not stop searching till it reads the last row as it doesn’t know that there is only one record with CustomerId = 50000 unless it reads the last row.
Let us now go to the Messages tab and see the IO and Time Statistics.
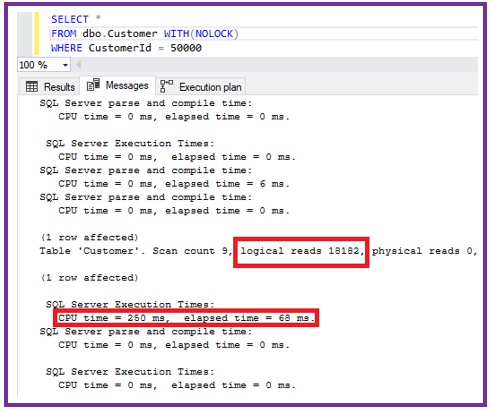
From the above IO and Time statistics of the query, we can see that it is reading 18,182 data pages. Each data page is of 8KB size, so to get one Customer record Sql server is reading 142 MB of data. And it is taking 250 millisecond CPU time.
From the above result we can observe that Sql Server is doing lot of IO and consuming CPU resource to fetch just one Customer record. If you see such things in your environment on any transactional table then there is something terrible wrong. You should immediately solve such problems. next sections will guide you through how such problems can be solved using Indexes.
HEAP Table
A table without a Clustered Index is called as a Heap Table. Frankly speaking we should never have a HEAP table in an Online Transaction Processing System (OLTP). There are some .01% edge case scenario where we may go for heap table if we need faster DML (INSERT, UPDATE, DELETE) operations. If we see any transactional table without a Clustered index then you can assume the table is badly designed.
The Customer table at the current state is a HEAP table, as it doesn’t have any Clustered index. In the above execution plan we have seen that Sql Server is doing a Table Scan, we see this operation of ” Table Scan” only for the HEAP Table. In case of a Table without a Clustered index , table data is stored in a heap structure. It means data is stored in an unordered way.
What is the Solution for the above query problem where it is reading 142 MB of data and using a quarter of a second to return just one customer record? Clustered Index is the Solution for the above query problems. In the next article in this series of articles on Indexes I will explain how Clustered Index solves these problems. Will post this article on Clustered Index next weekend, till then bye and be safe.