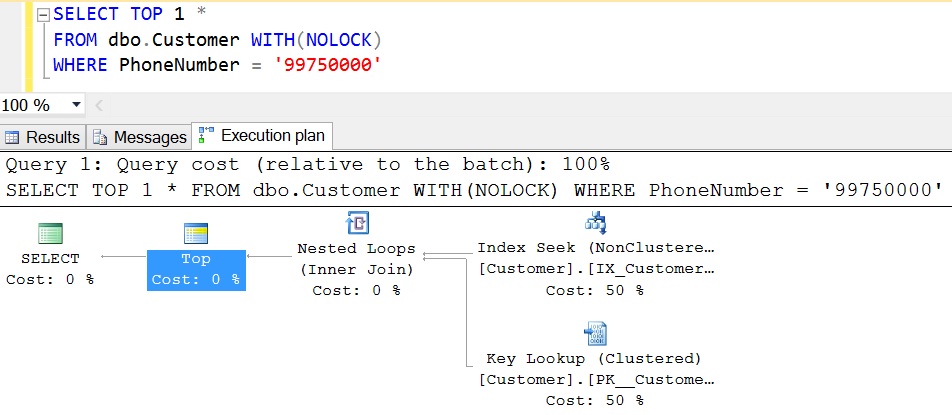
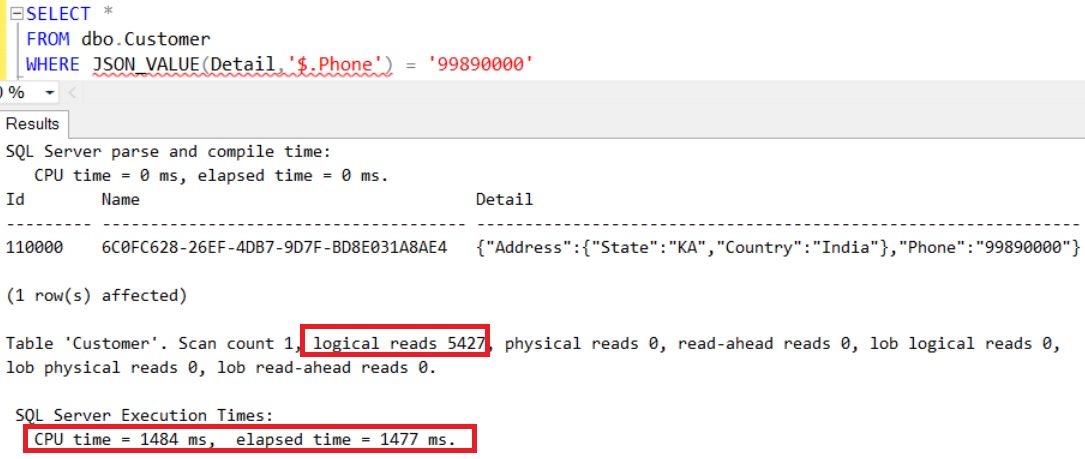
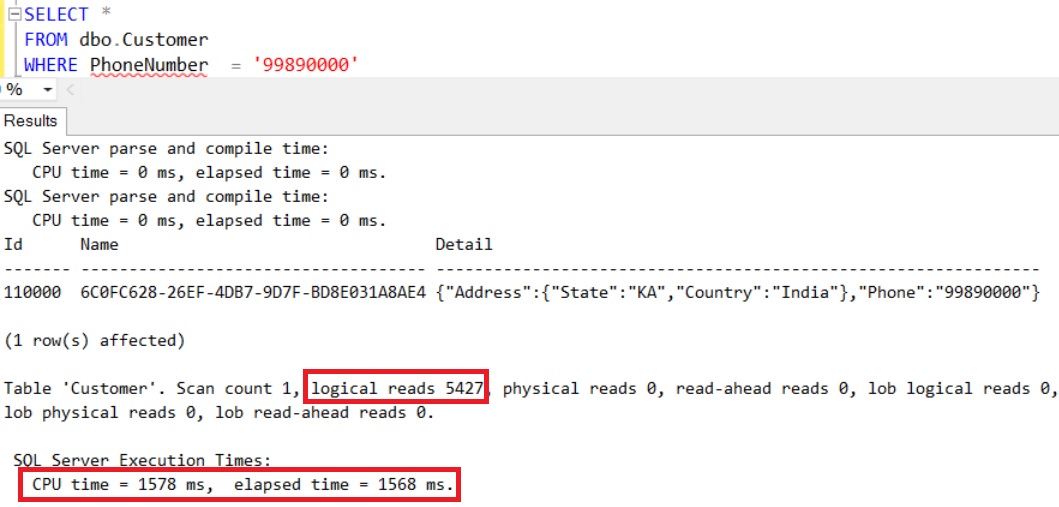
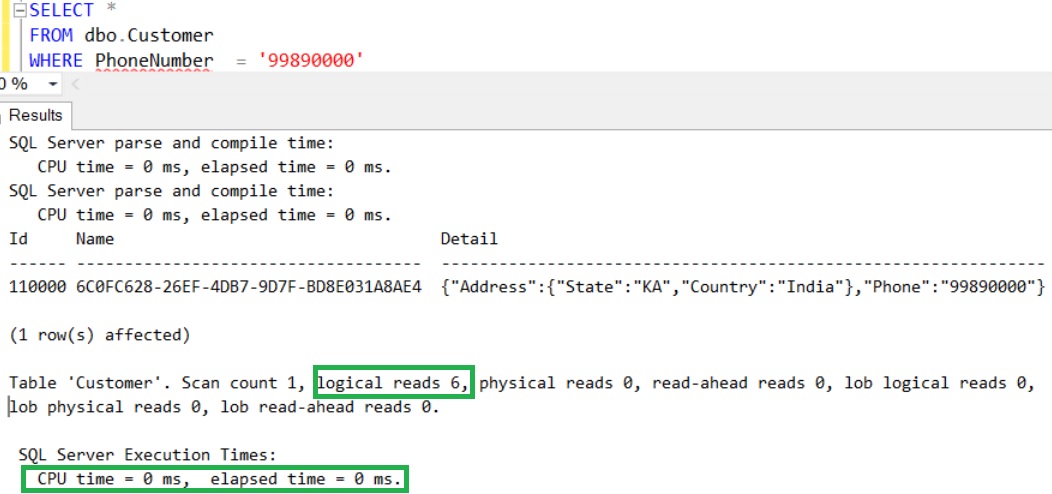
Live Query Statistics is one of the new feature introduced in Sql Server 2016, it basically provides the real-time live execution plan of an active running query to the Developer/DBA.
This SSMS feature is very helpful in checking the query execution progress for a long running queries, currently we don’t know for a long running queries where it is stuck or which specific operator is taking long time or how much percentage is completed or approximately how much extra duration required to complete it etc. This feature provides a way to know all these at any given point during the query execution.
It also helps in debugging the queries without needing to wait for the completion of the query execution. As soon as the query execution starts we can see the real-time live execution plan with moving dotted lines between the operators, operator execution progress, overall query execution progress etc.
Like Actual Execution Plan option, this option can be enabled before the query execution starts, it can’t be enabled when the query execution is in progress.
Like Actual execution plan, it will have some additional performance overhead on the overall query execution. So, enable only when it is required to troubleshoot or debug the query issues. Because of this avoid enabling the live query statistics on all the session, even though we have an option to enable it for all the sessions using an extended event query_post_execution_showplan.
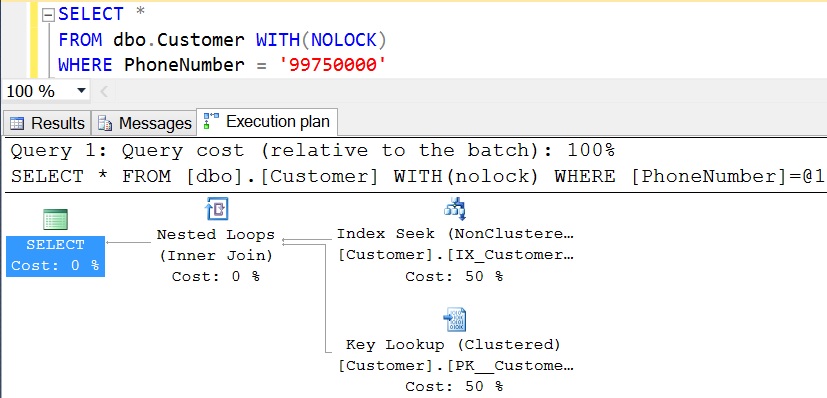
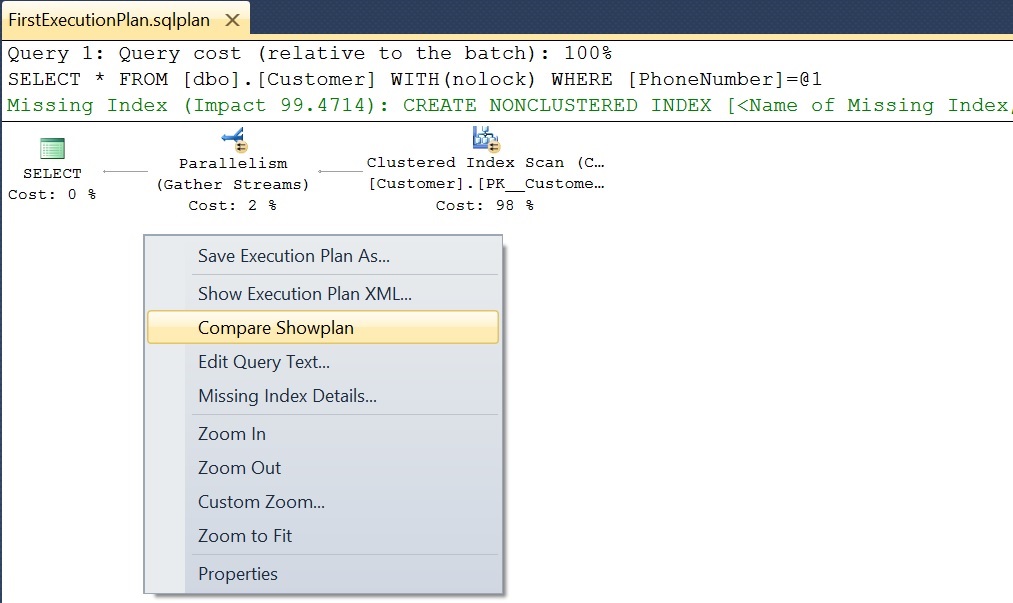
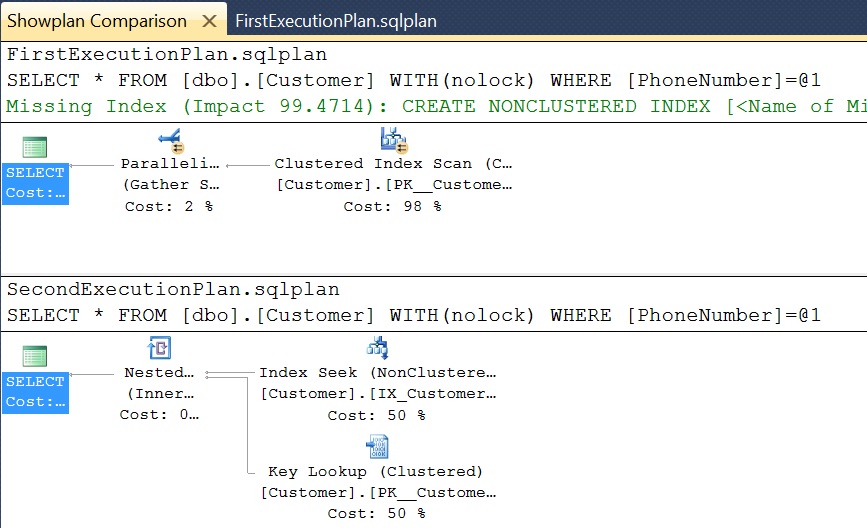
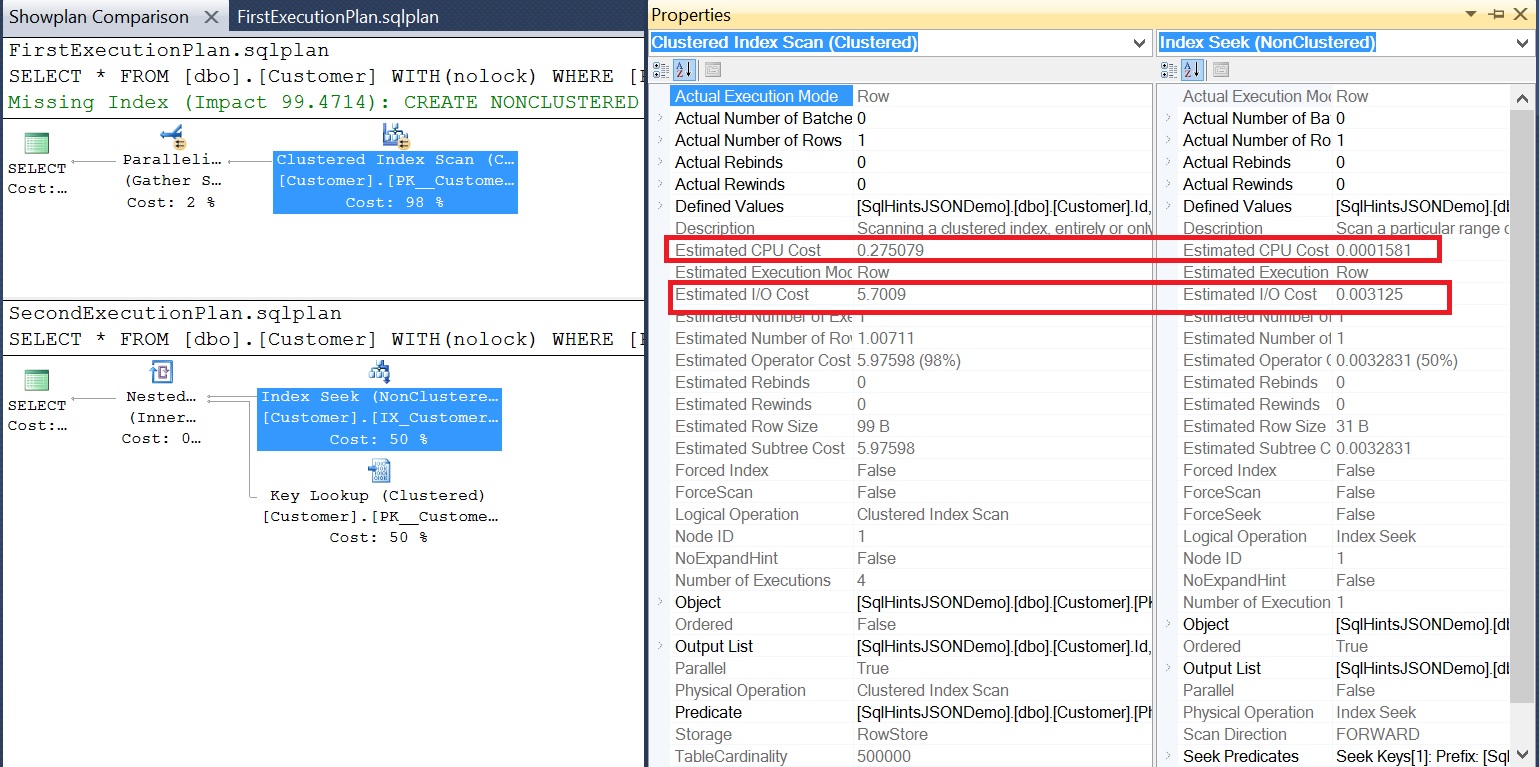
[ALSO READ] Compare Execution Plans in Sql Server 2016
Live query statistics feature in Sql Server 2016 provides various real-time query execution statistics like the below ones
- Overall Query Execution Progress:
It provides the overall query execution progress
We can see the moving dotted-lines between the operators where execution is not yet completed. And the dotted-lines turns to solid lines once the operator/complete query execution completes. It is somewhat similar to the one we see in the SSIS data flow. - At operator level it provides the real-time insights like the below ones:
- Operator execution progress
- Operator execution elapsed time
-
In the operator property window we can see real-time Actual number of rows, Operator Status, Elapsed time and various estimated values when operator execution is in progress like Estimated Number of rows, Estimated CPU Cost, Estimated I/O cost, Estimated Row Size etc. To open the operator property window, right-clicking on any operator and select the Properties option from the context menu.
Note: This article is based on the Sql Server 2016 CTP 3.1. Some of the views mentioned in this article may change in the RTM. Will try my best to keep this article updated
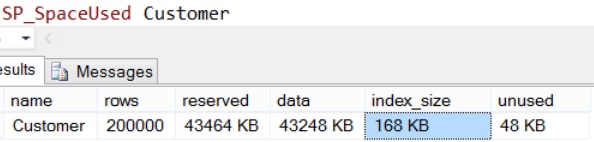
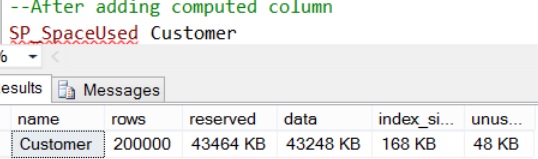
To understand this feature with examples let us create a demo Database with Customer Table as shown in the following image with 200,000 records by the following script.
--Create a demo database
CREATE DATABASE SqlHintsLQSDemo
GO
USE SqlHintsLQSDemo
GO
--Create customer table
CREATE TABLE dbo.Customer(
CustomerId INT IDENTITY(1,1) NOT NULL PRIMARY KEY,
Name NVARCHAR(50), PhoneNumber NVARCHAR(20),
CreationDate DATETIME, ChangeDate DATETIME)
--Populate customer table with sample 200000 records
INSERT INTO dbo.Customer(Name, CreationDate, ChangeDate)
SELECT TOP 200000 NEWID(), GETDATE(), GETDATE()
FROM SYS.all_columns SC1
CROSS JOIN SYS.all_columns SC2
GO
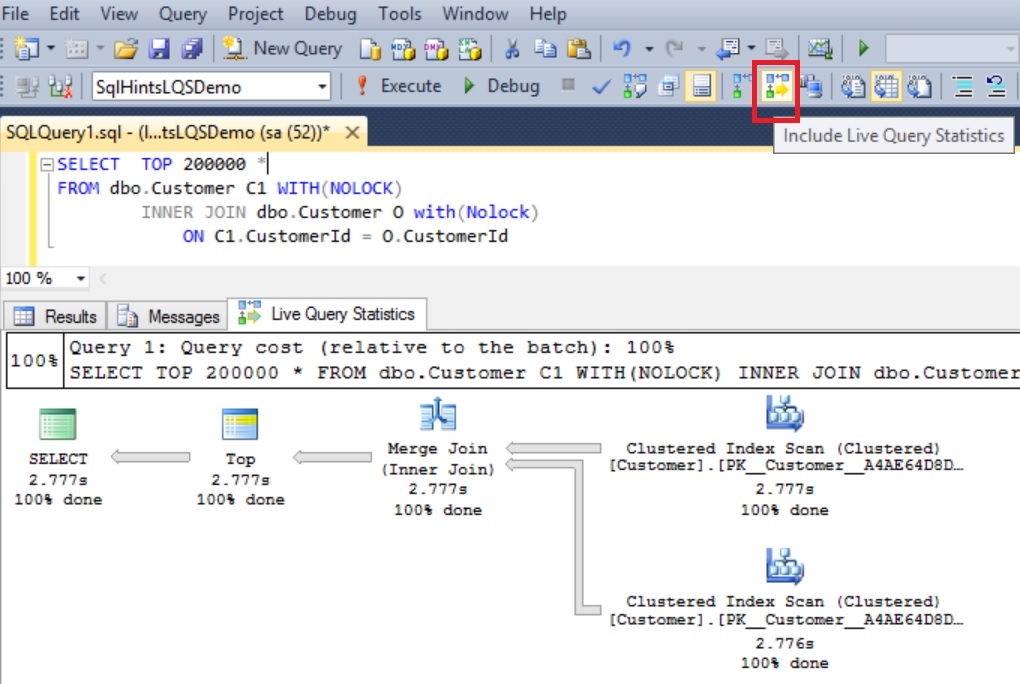
To get the live query execution plan, just like Actual Execution plan option we need to select the Include Live Query Statistics option as shown in the below image before executing the query
Let us execute the following query and observe it’s live execution plan in the following gif animation
SELECT TOP 200000 * FROM dbo.Customer C1 WITH(NOLOCK) INNER JOIN dbo.Customer O with(Nolock) ON C1.CustomerId = O.CustomerId
RESULT:
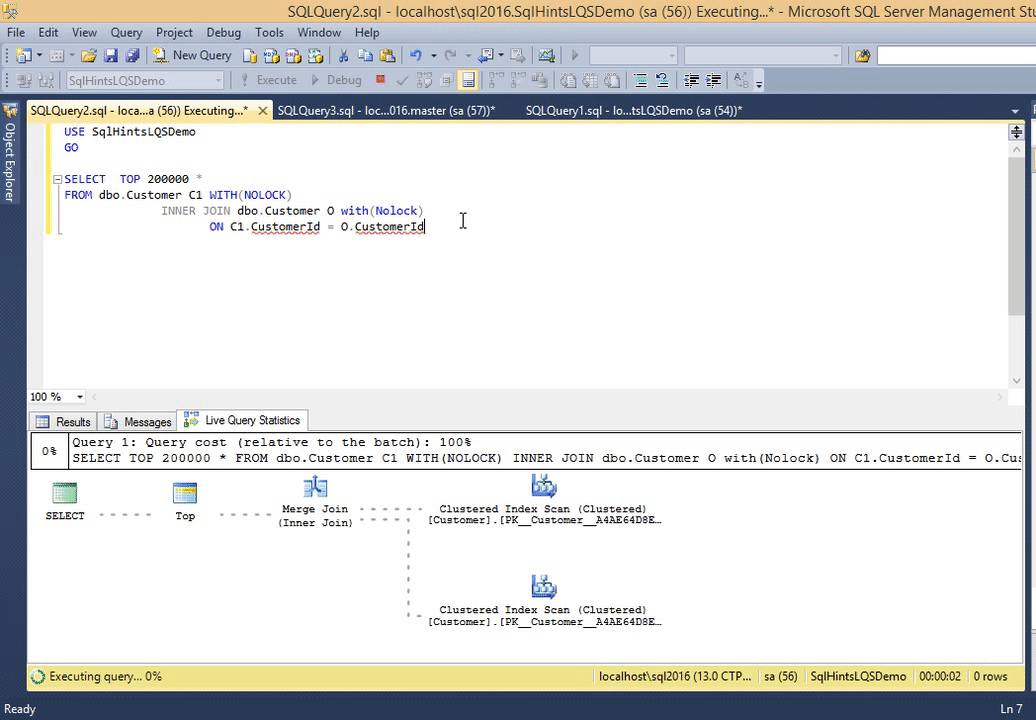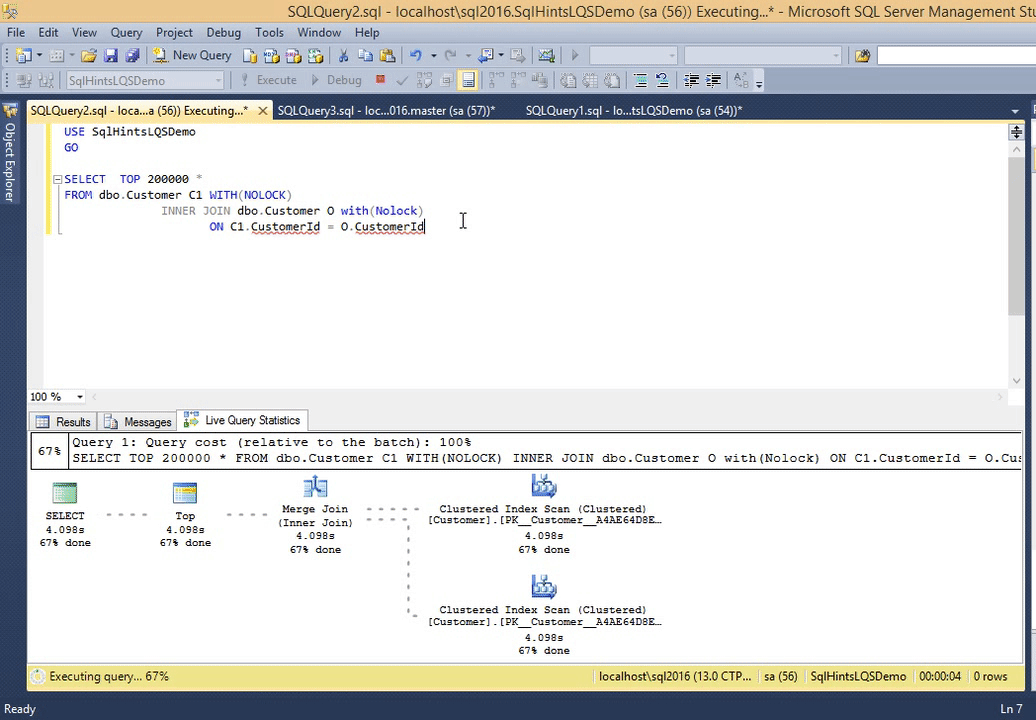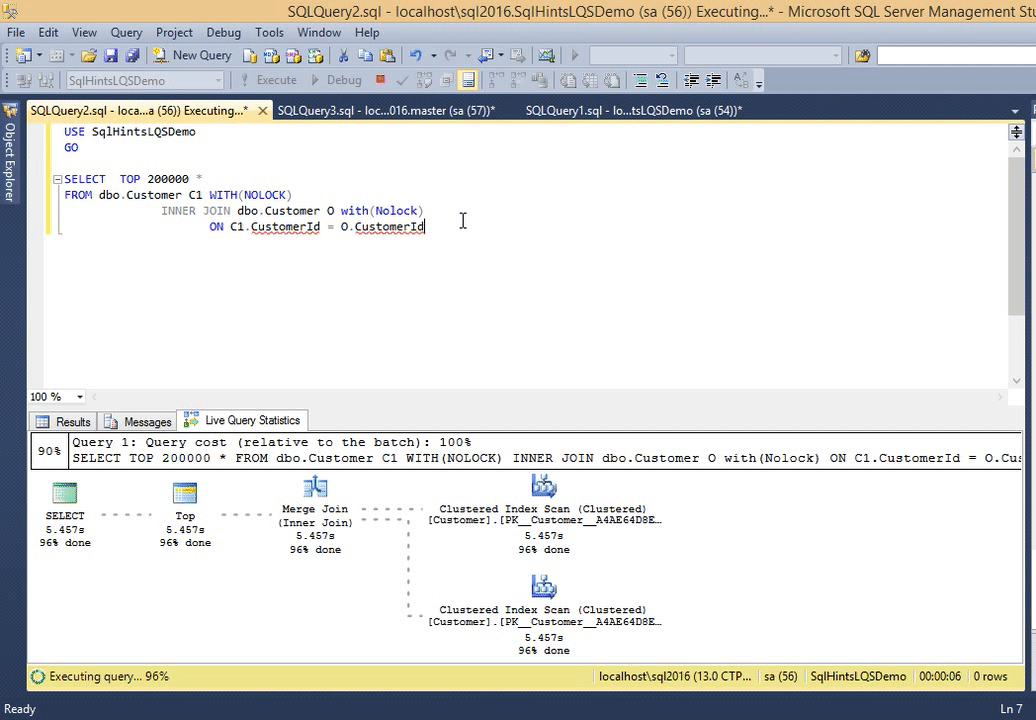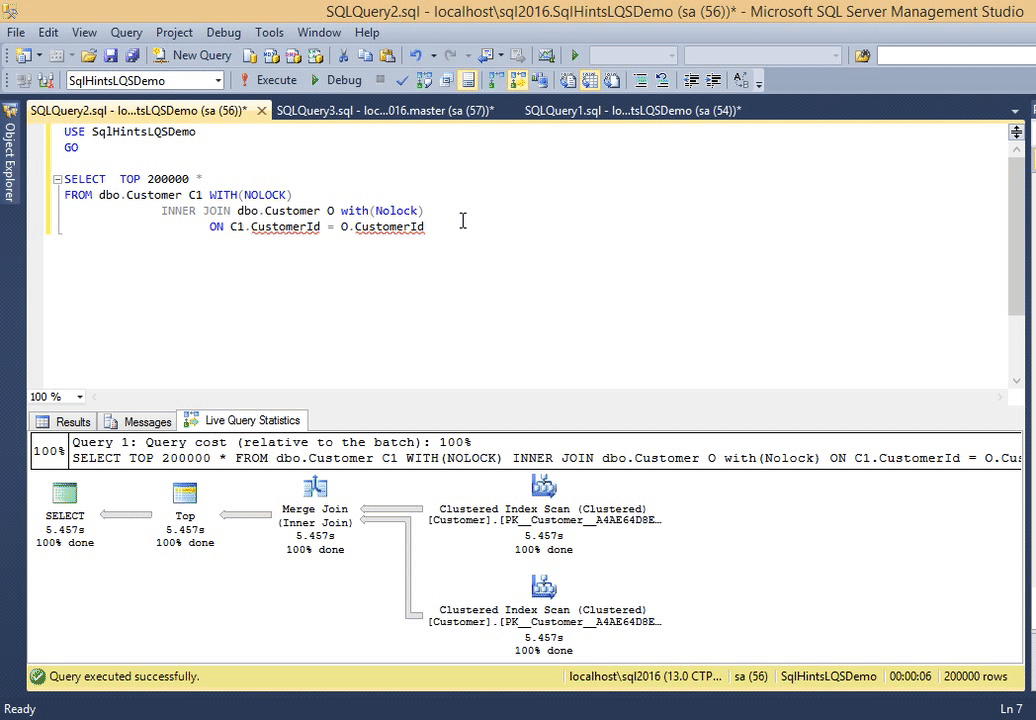
*Double click on the image to get the enlarged view
Let us update the Customer table statistics by the following statement. This statement is updating the Customer table stats that this table has only one record.
UPDATE STATISTICS dbo.Customer WITH ROWCOUNT = 1
Now re-execute the previous query and observer it’s live execution plan.
SELECT TOP 200000 * FROM dbo.Customer C1 WITH(NOLOCK) INNER JOIN dbo.Customer O with(Nolock) ON C1.CustomerId = O.CustomerId OPTION(RECOMPILE)
RESULT:
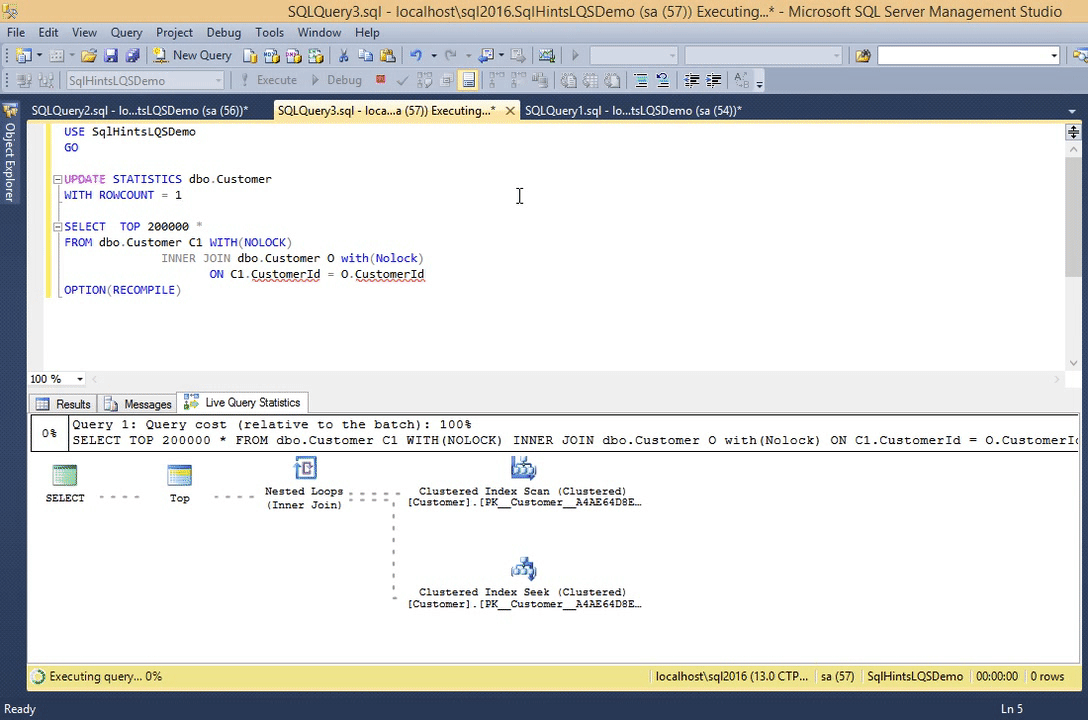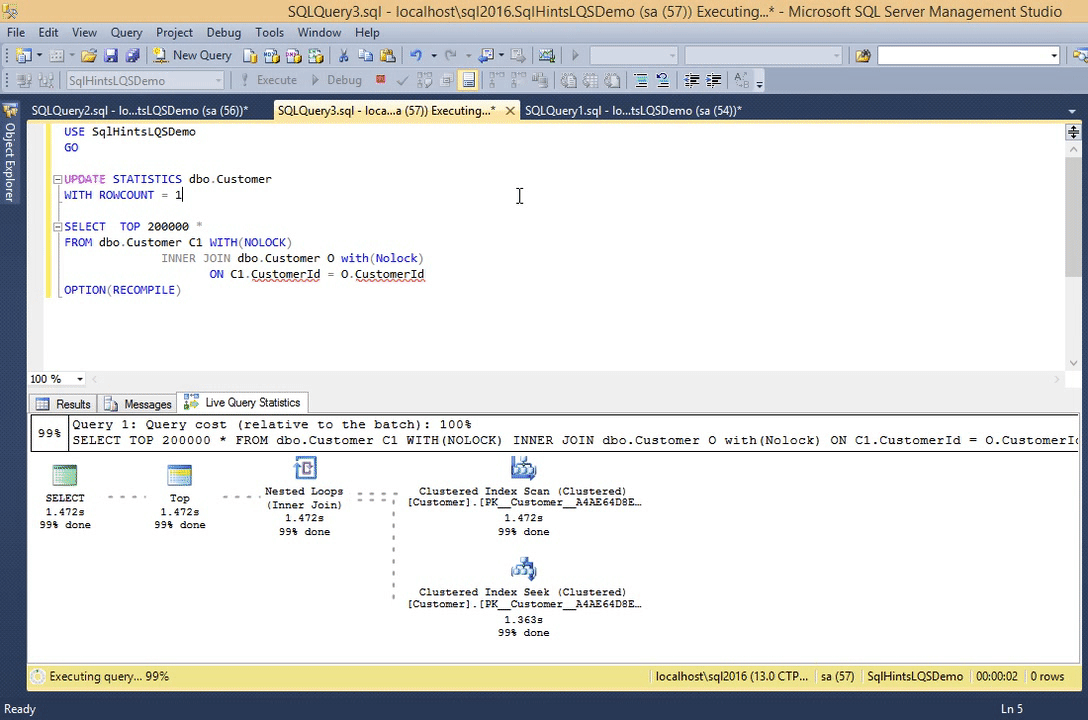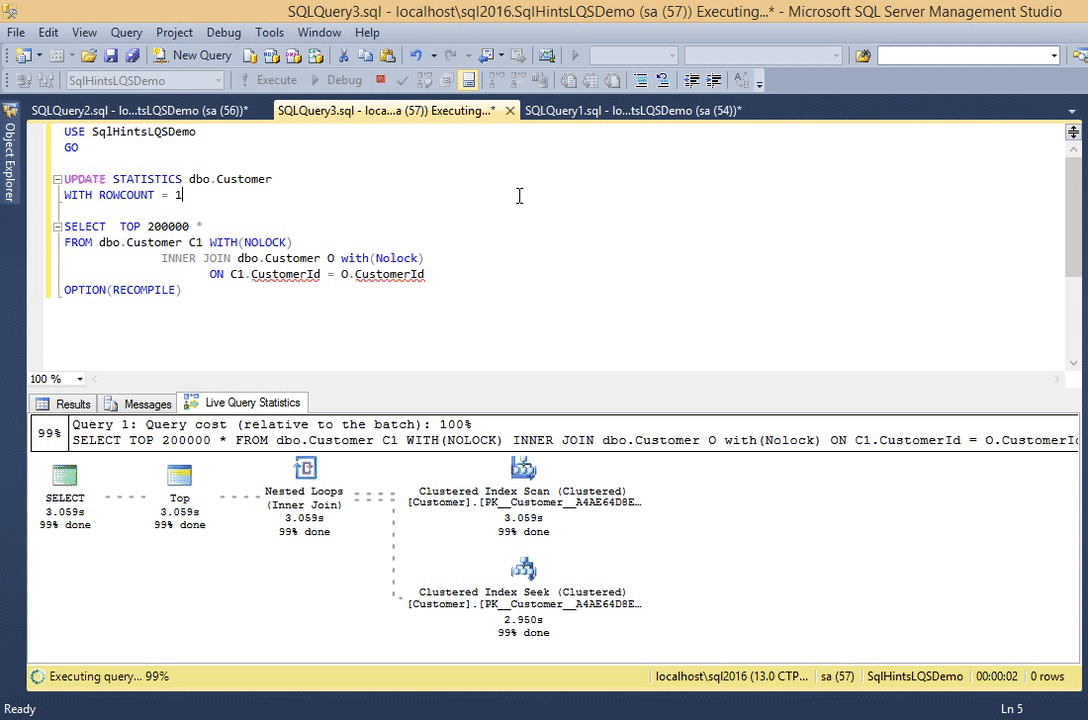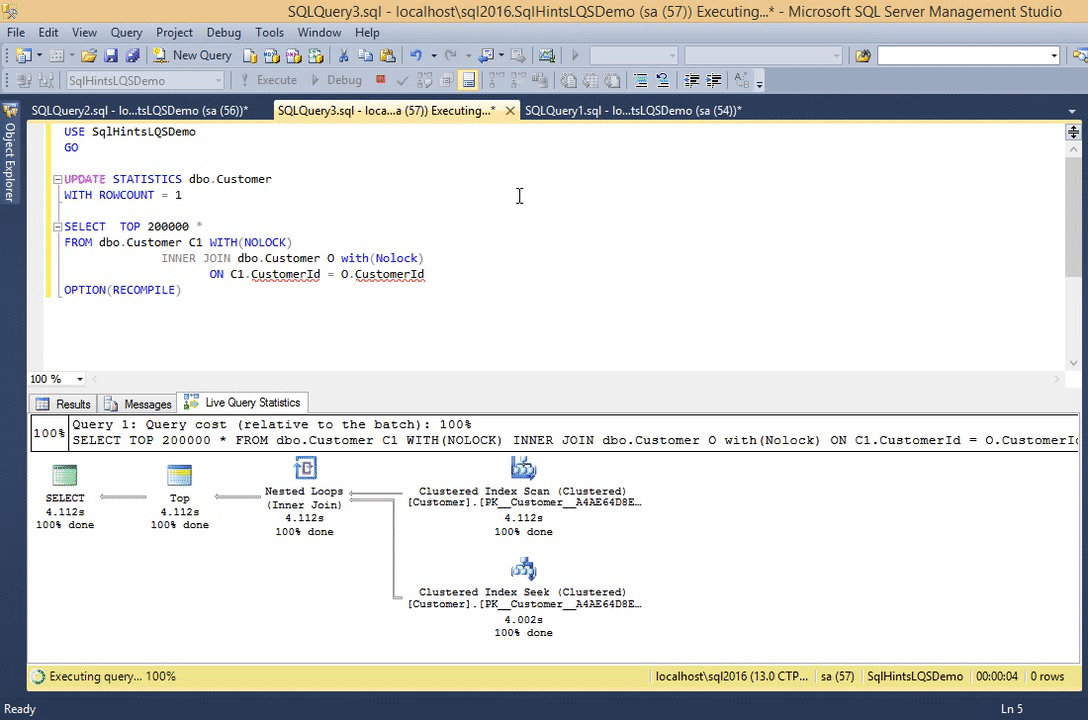
We can observe from this live execution plan that, all operators from the beginning are showing 99% completed, but in the previous example this % done was gradually increased from 0 to 100. So we can assume that some of the stats displayed in the live query statistics indirectly depends on the statistics which sql server maintains for the table, indexes etc
At this moment the live query statistics is not supported for the Natively Compiled Stored Procedure.
[ALSO READ]:
- Native JSON Support in Sql Server 2016
- DROP IF EXISTS Statement in Sql Server 2016
- Compare Execution Plans in Sql Server 2016
- Live Query Statistics in Sql Server 2016
- DATEDIFF_BIG Function in Sql Server 2016
- Difference between DATEDIFF and DATEDIFF_BIG functions in Sql Server
- SESSION_CONTEXT in Sql Server 2016