In Sql Server when we compare a column of lower data type to a value of higher data type, then it leads to an implicit conversion of the column of lower data type to the type of the value which we are comparing. This implicit conversion will result in Index Scan instead of an Index Seek and resulting in performance issue. This is one of the very common mistake resulting in performance bottleneck.
Let us understand how the implicit conversion results in a performance issue with an example. Let us create a Customer table as shown in the below image with sample one million records by executing the following script.

--Create Demo Database SqlHints101PerfTips
CREATE DATABASE SqlHints101PerfTips
GO
USE SqlHints101PerfTips
GO
--Create Demo Table Customers
CREATE TABLE dbo.Customers (
CustomerId INT IDENTITY(1,1) NOT NULL,
FirstName VARCHAR(50),
LastName VARCHAR(50),
PhoneNumber VARCHAR(10),
EmailAddress VARCHAR(50),
CreationDate DATETIME
)
GO
--Populate 1 million dummy customer records
INSERT INTO dbo.Customers (FirstName, LastName, PhoneNumber, EmailAddress, CreationDate)
SELECT TOP 1000000 REPLACE(NEWID(),'-',''), REPLACE(NEWID(),'-',''),
CAST( CAST(ROUND(RAND(CHECKSUM(NEWID()))*1000000000+4000000000,0) AS BIGINT) AS VARCHAR(10)),
REPLACE(NEWID(),'-','') + '@gmail.com',
DATEADD(HOUR,CAST(RAND(CHECKSUM(NEWID())) * 19999 as INT) + 1 ,'2006-01-01')
FROM sys.all_columns c1
CROSS JOIN sys.all_columns c2
GO
--Update one customer record with some know values
UPDATE dbo.Customers
SET FirstName = 'Basavaraj', LastName = 'Biradar',
PhoneNumber = '4545454545', EmailAddress = 'basav@gmail.com'
WHERE CustomerId = 100000
GO
--Create a PK and a Clustered Index on CustomerId column
ALTER TABLE dbo.Customers
ADD CONSTRAINT PK_Customers_CustomerId
PRIMARY KEY CLUSTERED (CustomerId)
GO
Create a Non-Clustered index on the EmailAddress column of the Customers Table by executing following statement:
CREATE NONCLUSTERED INDEX IX_Customers_EmailAddress on dbo.Customers (EmailAddress)
Execute the following script to create stored procedure to return customer details for the given input email address
CREATE PROCEDURE dbo.GetCustomerDetailsByEmailAddress @EmailAddress NVARCHAR(50) AS BEGIN SELECT * FROM dbo.Customers WHERE EmailAddress = @EmailAddress END
First let us now enable the execution plan in the Sql Server Management Studio by pressing the key stroke CTRL + M and also enable the IO and TIME statistics by executing the following statement
SET STATISTICS IO,TIME ON
Let us now execute the stored procedure GetCustomerDetailsByEmailAddress to return the details for the customer whose email address is basav@gmail.com.
EXEC GetCustomerDetailsByEmailAddress 'basav@gmail.com'
RESULT:

Let us go to the Execution Plan tab of the result and see the execution plan.
Execution Plan
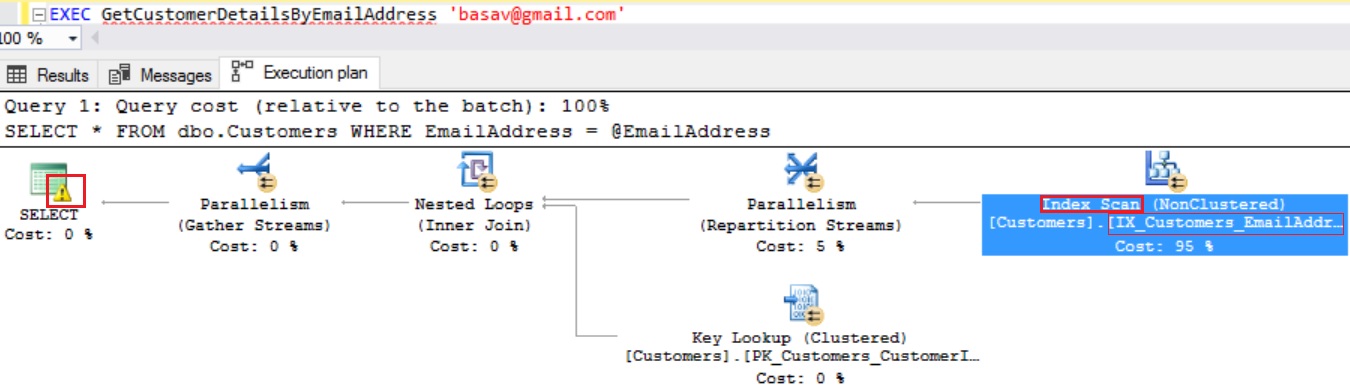
From the above execution plan, we can see that the index IX_Customers_EmailAddress on EmailAddress column is used, but it is doing an Index Scan instead of Index Seek. Let us hover over the Index Scan node in the execution plan and and observe the node properties.
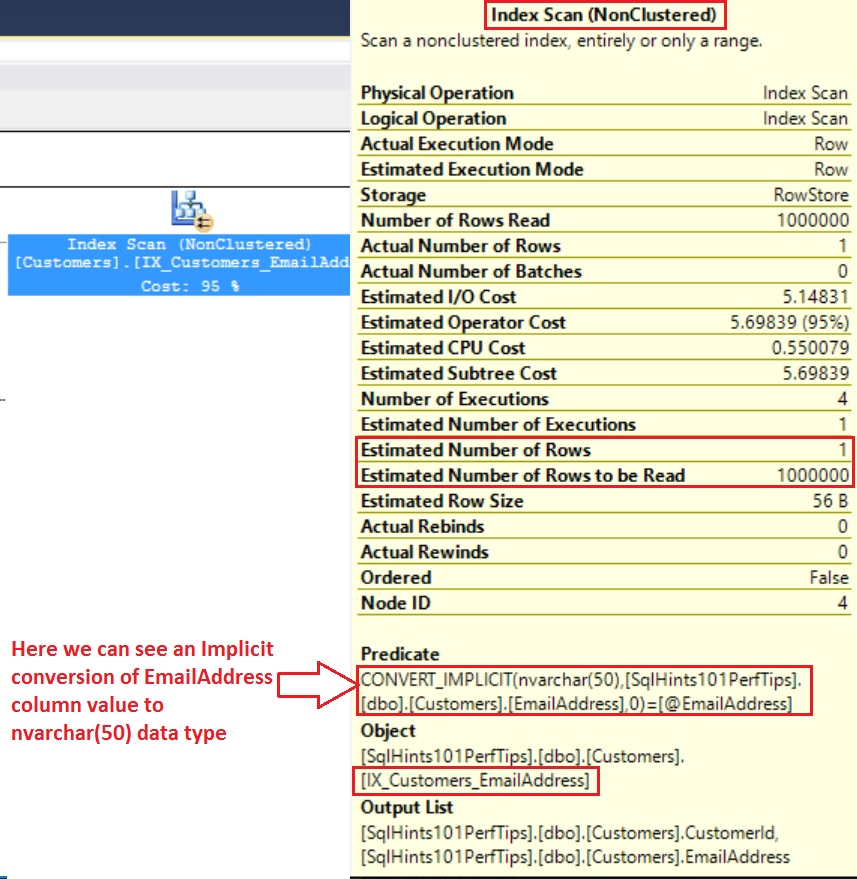
In the node properties we can clearly see an implicit conversion of the EmailAddress column of the Customers table to NVARCHAR(50) data type and scan of the Index IX_Customers_EmailAddress on the EmailAddress column.
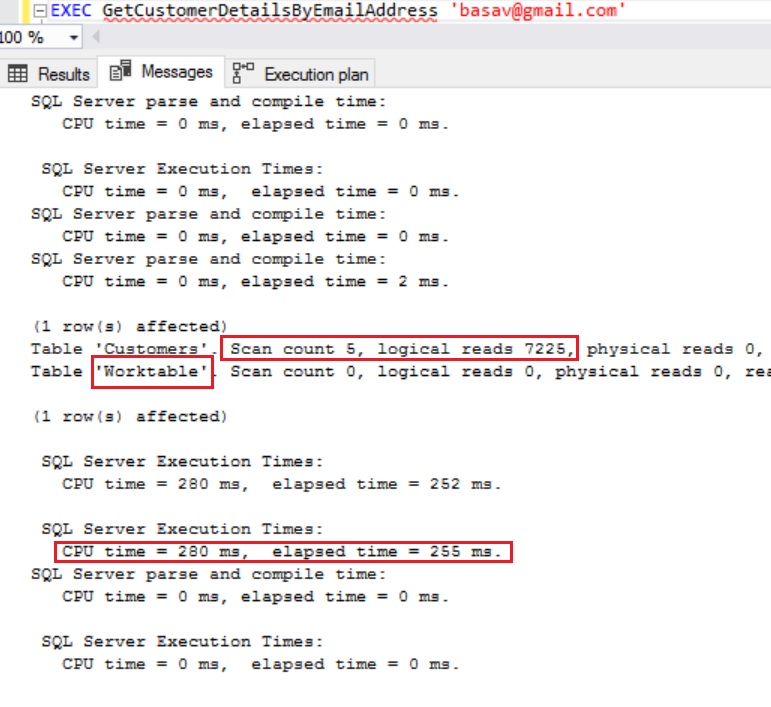
Let us go to Messages tab of the result and go over the IO and TIME statistics.
IO and TIME Statistics
Why Index Scan?
The stored procedure parameter @EmailAddress is of type NVARCHAR(50), where as the EmailAddress column in the Customers table is of type VARCHAR(50). As NVARCHAR is an higher data type compared to the VARCHAR data type, so sql is trying to convert the EmailAddress column value to NVARCHAR before comparing it with the NVARCHAR @EmailAddress parameter value
What is the solution?
One solution is to change the stored procedures input parameter @EmailAddress datatype from NVARCHAR(50) to VARCHAR(50) which matches with EmailAddress column data type in the Customer table. Alter the above stored procedure by executing the following statement:
ALTER PROCEDURE dbo.GetCustomerDetailsByEmailAddress
@EmailAddress VARCHAR(50)
AS
BEGIN
SELECT *
FROM dbo.Customers
WHERE EmailAddress = @EmailAddress
END
Now re-execute the stored procedure by executing the following statement
EXEC GetCustomerDetailsByEmailAddress 'basav@gmail.com'
RESULT:

From the above result we can see that there is no change in from the data returned by the SP.
Execution Plan
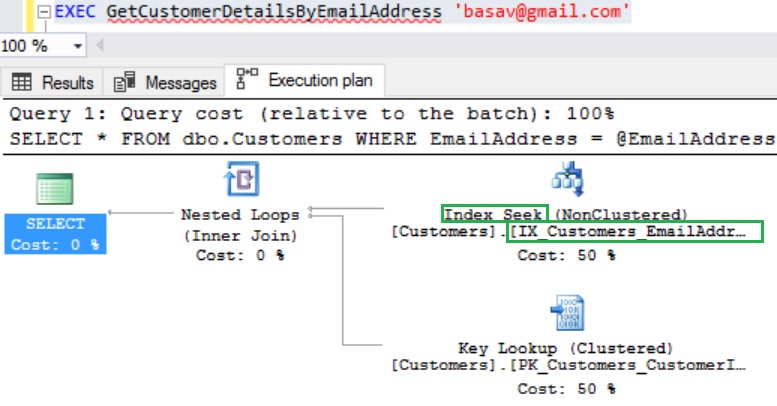
Now from the execution plan we can see that it is doing the Index Seek of the non-clustered index IX_Customers_EmailAddress on the EmailAddress column. Also the execution plan is very simplified and un-necessary parallelism and other overheads are no-longer present.
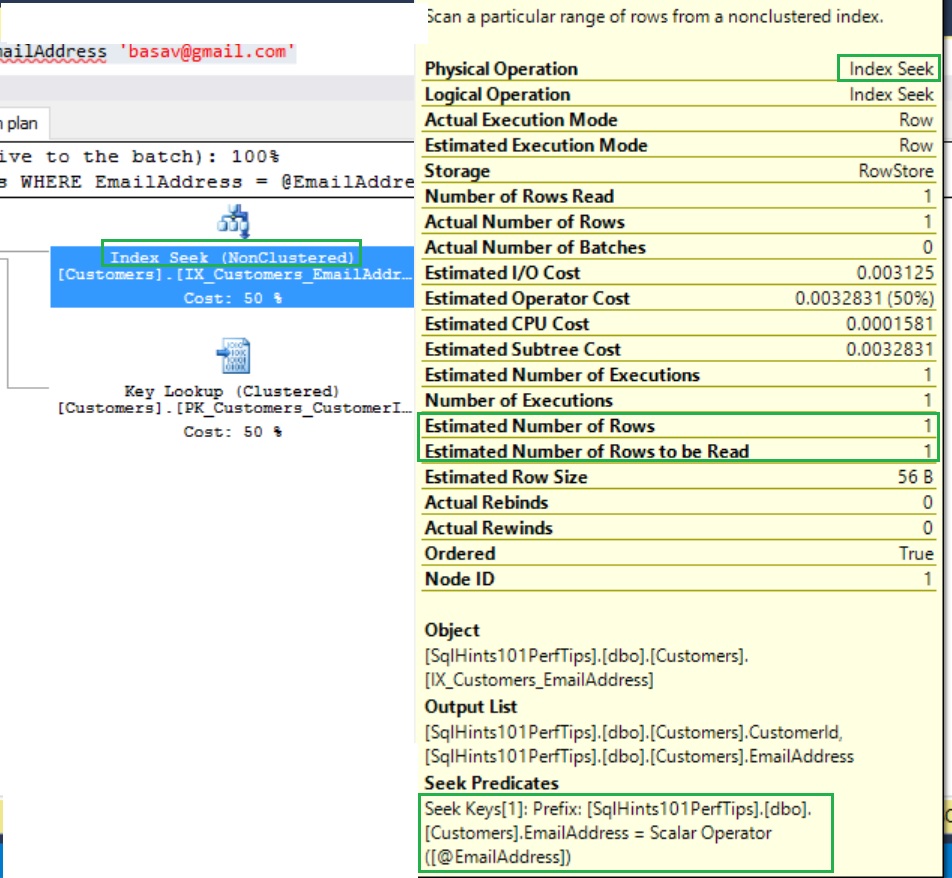
In the properties pop-up now we don’t see any implicit conversion and also Estimated number of rows to read also changed from one million to one.
IO and Time Statistics
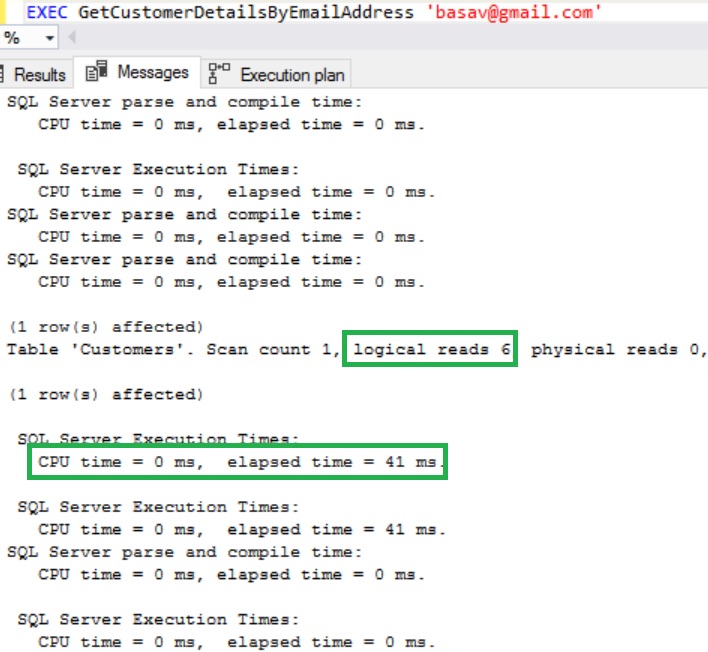
We can see that Logical reads have been reduced from 7225 to 6 and also CPU time has been reduced from 280 millseconds to 0 milliseconds. And also we don’t see the use of the WorkTable.
Conclusion:
In Sql Server when we compare a column of lower data type to a value of higher data type it leads to an implicit conversion of the column of lower data type to the type of the value which we are comparing. This implicit conversion will result in Index Scan instead of an Index Seek and resulting in performance issue. To avoid such performance issues, we should always make sure that the type of parameter and table column type should always match.